```
├── .gitattributes
├── .github/
├── ISSUE_TEMPLATE/
├── bug_report.md
├── feature_request.md
├── workflows/
├── python-publish.yaml
├── tests.yml
├── .gitignore
├── .pre-commit-config.yaml
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── img/
├── top-10-customers.png
├── vanna-readme-diagram.png
├── papers/
├── ai-sql-accuracy-2023-08-17.md
├── img/
├── accuracy-by-llm.png
├── accuracy-using-contextual-examples.png
├── accuracy-using-schema-only.png
├── accuracy-using-static-examples.png
├── chat-gpt-question.png
├── chatgpt-results.png
├── framework-for-sql-generation.png
├── question-flow.png
├── schema-only.png
├── sql-error.png
├── summary-table.png
├── summary.png
├── test-architecture.png
├── test-levers.png
├── using-contextually-relevant-examples.png
├── using-sql-examples.png
├── pyproject.toml
├── setup.cfg
├── src/
├── .editorconfig
├── vanna/
├── ZhipuAI/
├── ZhipuAI_Chat.py
├── ZhipuAI_embeddings.py
├── __init__.py
├── __init__.py
├── advanced/
├── __init__.py
├── anthropic/
├── __init__.py
├── anthropic_chat.py
├── azuresearch/
├── __init__.py
├── azuresearch_vector.py
├── base/
├── __init__.py
├── base.py
├── bedrock/
├── __init__.py
├── bedrock_converse.py
├── chromadb/
├── __init__.py
├── chromadb_vector.py
├── cohere/
├── __init__.py
├── cohere_chat.py
├── cohere_embeddings.py
├── deepseek/
├── __init__.py
├── deepseek_chat.py
├── exceptions/
├── __init__.py
├── faiss/
├── __init__.py
├── faiss.py
├── flask/
├── __init__.py
├── assets.py
```
## /.gitattributes
```gitattributes path="/.gitattributes"
*.ipynb linguist-detectable=false
```
## /.github/ISSUE_TEMPLATE/bug_report.md
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: ["bug"]
assignees: ''
---
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Error logs/Screenshots**
If applicable, add logs/screenshots to give more information about the issue.
**Desktop (please complete the following information where):**
- OS: [e.g. Ubuntu]
- Version: [e.g. 20.04]
- Python: [3.9]
- Vanna: [2.8.0]
**Additional context**
Add any other context about the problem here.
## /.github/ISSUE_TEMPLATE/feature_request.md
---
name: Feature request
about: Suggest an idea for this project
title: ''
labels: ["enhancements"]
assignees: ''
---
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
## /.github/workflows/python-publish.yaml
```yaml path="/.github/workflows/python-publish.yaml"
# This workflow will upload a Python Package using Twine when a release is created
# For more information see: https://docs.github.com/en/actions/automating-builds-and-tests/building-and-testing-python#publishing-to-package-registries
# This workflow uses actions that are not certified by GitHub.
# They are provided by a third-party and are governed by
# separate terms of service, privacy policy, and support
# documentation.
name: Upload Python Package
on:
release:
types: [published]
permissions:
contents: read
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v3
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install build
- name: Build package
run: python -m build
- name: Publish package
uses: pypa/gh-action-pypi-publish@27b31702a0e7fc50959f5ad993c78deac1bdfc29
with:
user: __token__
password: ${{ secrets.PYPI_API_TOKEN }}
```
## /.github/workflows/tests.yml
```yml path="/.github/workflows/tests.yml"
name: Basic Integration Tests
on:
push:
branches:
- main
permissions:
contents: read
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python 3.10
uses: actions/setup-python@v5
with:
python-version: "3.10"
- name: Install pip
run: |
python -m pip install --upgrade pip
pip install tox
- name: Run tests
env:
PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION: python
VANNA_API_KEY: ${{ secrets.VANNA_API_KEY }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
MISTRAL_API_KEY: ${{ secrets.MISTRAL_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USERNAME: ${{ secrets.SNOWFLAKE_USERNAME }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
run: tox -e py310
```
## /.gitignore
```gitignore path="/.gitignore"
build
**.egg-info
venv
.DS_Store
notebooks/*
tests/__pycache__
__pycache__/
.idea
.coverage
docs/*.html
.ipynb_checkpoints/
.tox/
notebooks/chroma.sqlite3
dist
.env
*.sqlite
htmlcov
chroma.sqlite3
*.bin
.coverage.*
milvus.db
.milvus.db.lock
```
## /.pre-commit-config.yaml
```yaml path="/.pre-commit-config.yaml"
exclude: 'docs|node_modules|migrations|.git|.tox|assets.py'
default_stages: [ commit ]
fail_fast: true
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-merge-conflict
- id: debug-statements
- id: mixed-line-ending
- repo: https://github.com/pycqa/isort
rev: 5.12.0
hooks:
- id: isort
args: [ "--profile", "black", "--filter-files" ]
```
## /CONTRIBUTING.md
# Contributing
## Setup
```bash
git clone https://github.com/vanna-ai/vanna.git
cd vanna/
python3 -m venv venv
source venv/bin/activate
# install package in editable mode
pip install -e '.[all]' tox pre-commit
# Setup pre-commit hooks
pre-commit install
# List dev targets
tox list
# Run tests
tox -e py310
```
## Running the test on a Mac
```bash
tox -e mac
```
## Do this before you submit a PR:
Find the most relevant sample notebook and then replace the install command with:
```bash
%pip install 'git+https://github.com/vanna-ai/vanna@your-branch#egg=vanna[chromadb,snowflake,openai]'
```
Run the necessary cells and verify that it works as expected in a real-world scenario.
## /LICENSE
``` path="/LICENSE"
MIT License
Copyright (c) 2024 Vanna.AI
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
```
## /README.md
| GitHub | PyPI | Documentation | Gurubase |
| ------ | ---- | ------------- | -------- |
| [](https://github.com/vanna-ai/vanna) | [](https://pypi.org/project/vanna/) | [](https://vanna.ai/docs/) | [](https://gurubase.io/g/vanna) |
# Vanna
Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality.
https://github.com/vanna-ai/vanna/assets/7146154/1901f47a-515d-4982-af50-f12761a3b2ce

## How Vanna works

Vanna works in two easy steps - train a RAG "model" on your data, and then ask questions which will return SQL queries that can be set up to automatically run on your database.
1. **Train a RAG "model" on your data**.
2. **Ask questions**.

If you don't know what RAG is, don't worry -- you don't need to know how this works under the hood to use it. You just need to know that you "train" a model, which stores some metadata and then use it to "ask" questions.
See the [base class](https://github.com/vanna-ai/vanna/blob/main/src/vanna/base/base.py) for more details on how this works under the hood.
## User Interfaces
These are some of the user interfaces that we've built using Vanna. You can use these as-is or as a starting point for your own custom interface.
- [Jupyter Notebook](https://vanna.ai/docs/postgres-openai-vanna-vannadb/)
- [vanna-ai/vanna-streamlit](https://github.com/vanna-ai/vanna-streamlit)
- [vanna-ai/vanna-flask](https://github.com/vanna-ai/vanna-flask)
- [vanna-ai/vanna-slack](https://github.com/vanna-ai/vanna-slack)
## Supported LLMs
- [OpenAI](https://github.com/vanna-ai/vanna/tree/main/src/vanna/openai)
- [Anthropic](https://github.com/vanna-ai/vanna/tree/main/src/vanna/anthropic)
- [Gemini](https://github.com/vanna-ai/vanna/blob/main/src/vanna/google/gemini_chat.py)
- [HuggingFace](https://github.com/vanna-ai/vanna/blob/main/src/vanna/hf/hf.py)
- [AWS Bedrock](https://github.com/vanna-ai/vanna/tree/main/src/vanna/bedrock)
- [Ollama](https://github.com/vanna-ai/vanna/tree/main/src/vanna/ollama)
- [Qianwen](https://github.com/vanna-ai/vanna/tree/main/src/vanna/qianwen)
- [Qianfan](https://github.com/vanna-ai/vanna/tree/main/src/vanna/qianfan)
- [Zhipu](https://github.com/vanna-ai/vanna/tree/main/src/vanna/ZhipuAI)
## Supported VectorStores
- [AzureSearch](https://github.com/vanna-ai/vanna/tree/main/src/vanna/azuresearch)
- [Opensearch](https://github.com/vanna-ai/vanna/tree/main/src/vanna/opensearch)
- [PgVector](https://github.com/vanna-ai/vanna/tree/main/src/vanna/pgvector)
- [PineCone](https://github.com/vanna-ai/vanna/tree/main/src/vanna/pinecone)
- [ChromaDB](https://github.com/vanna-ai/vanna/tree/main/src/vanna/chromadb)
- [FAISS](https://github.com/vanna-ai/vanna/tree/main/src/vanna/faiss)
- [Marqo](https://github.com/vanna-ai/vanna/tree/main/src/vanna/marqo)
- [Milvus](https://github.com/vanna-ai/vanna/tree/main/src/vanna/milvus)
- [Qdrant](https://github.com/vanna-ai/vanna/tree/main/src/vanna/qdrant)
- [Weaviate](https://github.com/vanna-ai/vanna/tree/main/src/vanna/weaviate)
- [Oracle](https://github.com/vanna-ai/vanna/tree/main/src/vanna/oracle)
## Supported Databases
- [PostgreSQL](https://www.postgresql.org/)
- [MySQL](https://www.mysql.com/)
- [PrestoDB](https://prestodb.io/)
- [Apache Hive](https://hive.apache.org/)
- [ClickHouse](https://clickhouse.com/)
- [Snowflake](https://www.snowflake.com/en/)
- [Oracle](https://www.oracle.com/)
- [Microsoft SQL Server](https://www.microsoft.com/en-us/sql-server/sql-server-downloads)
- [BigQuery](https://cloud.google.com/bigquery)
- [SQLite](https://www.sqlite.org/)
- [DuckDB](https://duckdb.org/)
## Getting started
See the [documentation](https://vanna.ai/docs/) for specifics on your desired database, LLM, etc.
If you want to get a feel for how it works after training, you can try this [Colab notebook](https://vanna.ai/docs/app/).
### Install
```bash
pip install vanna
```
There are a number of optional packages that can be installed so see the [documentation](https://vanna.ai/docs/) for more details.
### Import
See the [documentation](https://vanna.ai/docs/) if you're customizing the LLM or vector database.
```python
# The import statement will vary depending on your LLM and vector database. This is an example for OpenAI + ChromaDB
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
# See the documentation for other options
```
## Training
You may or may not need to run these `vn.train` commands depending on your use case. See the [documentation](https://vanna.ai/docs/) for more details.
These statements are shown to give you a feel for how it works.
### Train with DDL Statements
DDL statements contain information about the table names, columns, data types, and relationships in your database.
```python
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
```
### Train with Documentation
Sometimes you may want to add documentation about your business terminology or definitions.
```python
vn.train(documentation="Our business defines XYZ as ...")
```
### Train with SQL
You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
```python
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")
```
## Asking questions
```python
vn.ask("What are the top 10 customers by sales?")
```
You'll get SQL
```sql
SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;
```
If you've connected to a database, you'll get the table:
|
CUSTOMER_NAME |
TOTAL_SALES |
| 0 |
Customer#000143500 |
6757566.0218 |
| 1 |
Customer#000095257 |
6294115.3340 |
| 2 |
Customer#000087115 |
6184649.5176 |
| 3 |
Customer#000131113 |
6080943.8305 |
| 4 |
Customer#000134380 |
6075141.9635 |
| 5 |
Customer#000103834 |
6059770.3232 |
| 6 |
Customer#000069682 |
6057779.0348 |
| 7 |
Customer#000102022 |
6039653.6335 |
| 8 |
Customer#000098587 |
6027021.5855 |
| 9 |
Customer#000064660 |
5905659.6159 |
You'll also get an automated Plotly chart:

## RAG vs. Fine-Tuning
RAG
- Portable across LLMs
- Easy to remove training data if any of it becomes obsolete
- Much cheaper to run than fine-tuning
- More future-proof -- if a better LLM comes out, you can just swap it out
Fine-Tuning
- Good if you need to minimize tokens in the prompt
- Slow to get started
- Expensive to train and run (generally)
## Why Vanna?
1. **High accuracy on complex datasets.**
- Vanna’s capabilities are tied to the training data you give it
- More training data means better accuracy for large and complex datasets
2. **Secure and private.**
- Your database contents are never sent to the LLM or the vector database
- SQL execution happens in your local environment
3. **Self learning.**
- If using via Jupyter, you can choose to "auto-train" it on the queries that were successfully executed
- If using via other interfaces, you can have the interface prompt the user to provide feedback on the results
- Correct question to SQL pairs are stored for future reference and make the future results more accurate
4. **Supports any SQL database.**
- The package allows you to connect to any SQL database that you can otherwise connect to with Python
5. **Choose your front end.**
- Most people start in a Jupyter Notebook.
- Expose to your end users via Slackbot, web app, Streamlit app, or a custom front end.
## Extending Vanna
Vanna is designed to connect to any database, LLM, and vector database. There's a [VannaBase](https://github.com/vanna-ai/vanna/blob/main/src/vanna/base/base.py) abstract base class that defines some basic functionality. The package provides implementations for use with OpenAI and ChromaDB. You can easily extend Vanna to use your own LLM or vector database. See the [documentation](https://vanna.ai/docs/) for more details.
## Vanna in 100 Seconds
https://github.com/vanna-ai/vanna/assets/7146154/eb90ee1e-aa05-4740-891a-4fc10e611cab
## More resources
- [Full Documentation](https://vanna.ai/docs/)
- [Website](https://vanna.ai)
- [Discord group for support](https://discord.gg/qUZYKHremx)
## /img/top-10-customers.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/img/top-10-customers.png
## /img/vanna-readme-diagram.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/img/vanna-readme-diagram.png
## /papers/ai-sql-accuracy-2023-08-17.md
# AI SQL Accuracy: Testing different LLMs + context strategies to maximize SQL generation accuracy
_2023-08-17_
## TLDR
The promise of having an autonomous AI agent that can answer business users’ plain English questions is an attractive but thus far elusive proposition. Many have tried, with limited success, to get ChatGPT to write. The failure is primarily due of a lack of the LLM's knowledge of the particular dataset it’s being asked to query.
In this paper, **we show that context is everything, and with the right context, we can get from ~3% accuracy to ~80% accuracy**. We go through three different context strategies, and showcase one that is the clear winner - where we combine schema definitions, documentation, and prior SQL queries with a relevance search.
We also compare a few different LLMs - including Google Bison, GPT 3.5, GPT 4, and a brief attempt with Llama 2. While **GPT 4 takes the crown of the best overall LLM for generating SQL**, Google’s Bison is roughly equivalent when enough context is provided.
Finally, we show how you can use the methods demonstrated here to generate SQL for your database.
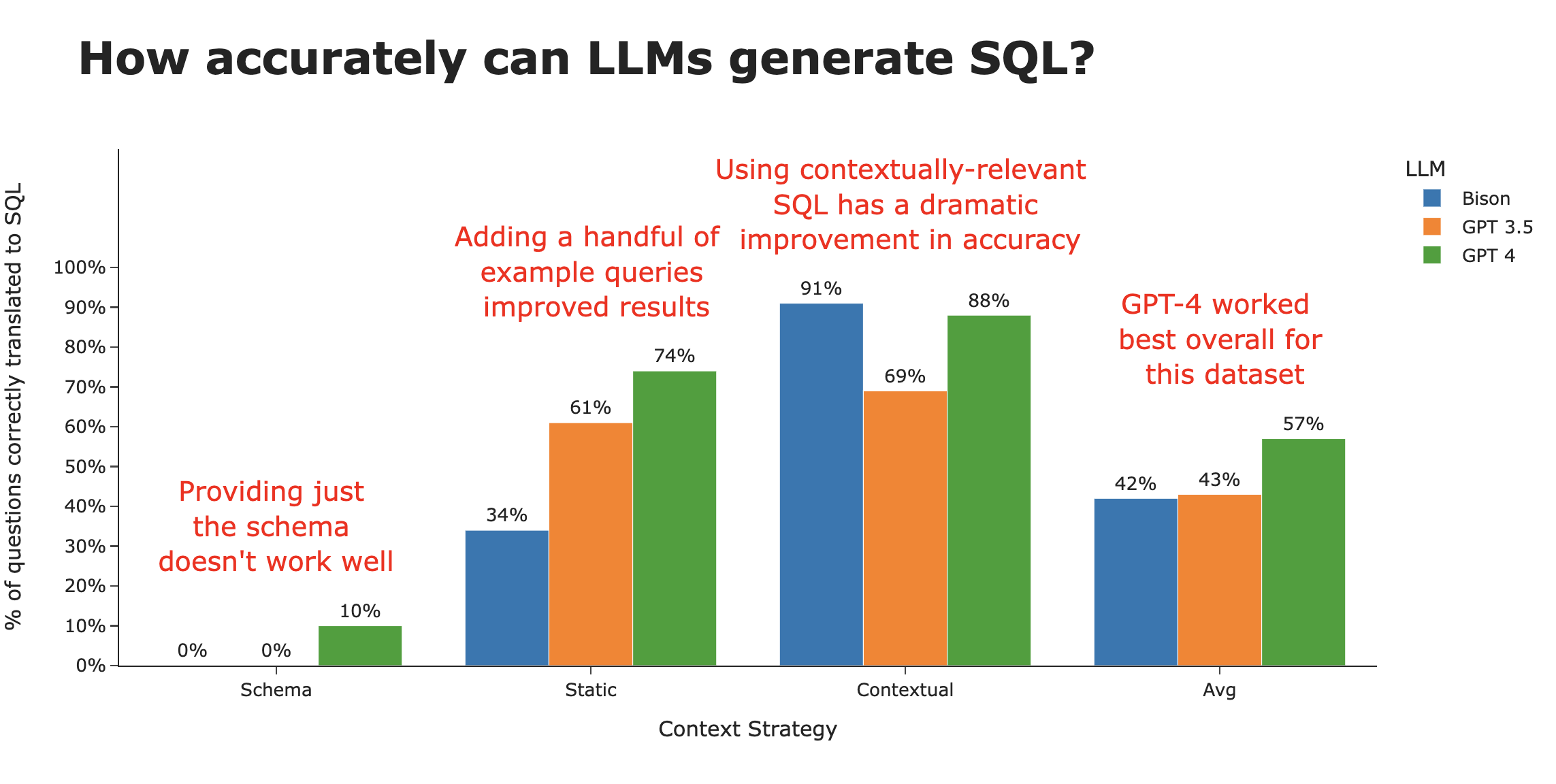
Here's a summary of our key findings -
## Table of Contents
* [Why use AI to generate SQL?](#why-use-ai-to-generate-sql)
* [Setting up architecture of the test](#setting-up-architecture-of-the-test)
* [Setting up the test levers](#setting-up-the-test-levers)
* [Choosing a dataset](#choosing-a-dataset)
* [Choosing the questions](#choosing-the-questions)
* [Choosing the prompt](#choosing-the-prompt)
* [Choosing the LLMs (Foundational models)](#choosing-the-llms-foundational-models)
* [Choosing the context](#choosing-the-context)
* [Using ChatGPT to generate SQL](#using-chatgpt-to-generate-sql)
* [Using schema only](#using-schema-only)
* [Using SQL examples](#using-sql-examples)
* [Using contextually relevant examples](#using-contextually-relevant-examples)
* [Analyzing the results](#analyzing-the-results)
* [Next steps to getting accuracy even higher](#next-steps-to-getting-accuracy-even-higher)
* [Use AI to write SQL for your dataset](#use-ai-to-write-sql-for-your-dataset)
## Why use AI to generate SQL?
Many organizations have now adopted some sort of data warehouse or data lake - a repository of a lot of the organization’s critical data that is queryable for analytical purposes. This ocean of data is brimming with potential insights, but only a small fraction of people in an enterprise have the two skills required to harness the data —
1. A solid comprehension of **advanced SQL**, and
2. A comprehensive knowledge of the **organization’s unique data structure & schema**
The number of people with both of the above is not only vanishingly small, but likely not the same people that have the majority of the questions.
**So what actually happens inside organizations?** Business users, like product managers, sales managers, and executives, have data questions that will inform business decisions and strategy. They’ll first check dashboards, but most questions are ad hoc and specific, and the answers aren’t available, so they’ll ask a data analyst or engineer - whomever possesses the combination of skills above. These people are busy, and take a while to get to the request, and as soon as they get an answer, the business user has follow up questions.
**This process is painful** for both the business user (long lead times to get answers) and the analyst (distracts from their main projects), and leads to many potential insights being lost.
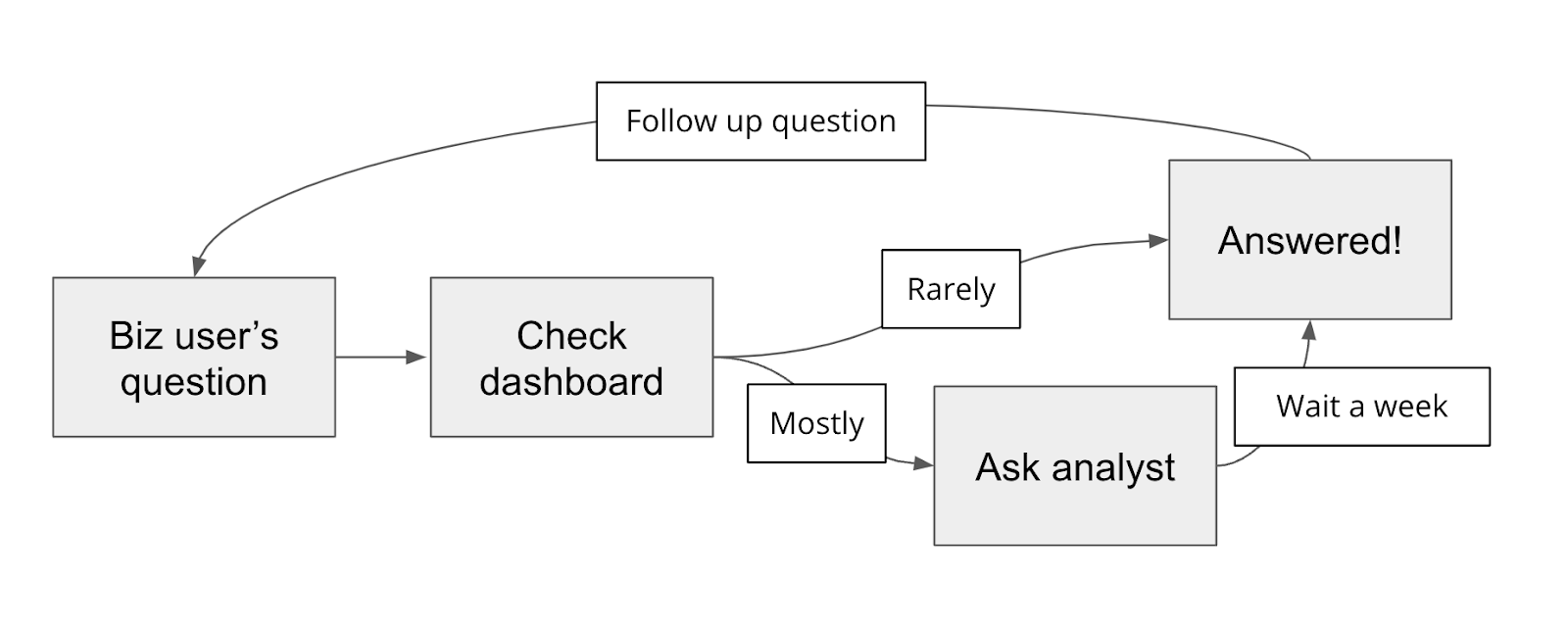
**Enter generative AI!** LLMs potentially give the opportunity to business users to query the database in plain English (with the LLMs doing the SQL translation), and we have heard from dozens of companies that this would be a game changer for their data teams and even their businesses.
**The key challenge is generating accurate SQL for complex and messy databases**. Plenty of people we’ve spoken with have tried to use ChatGPT to write SQL with limited success and a lot of pain. Many have given up and reverted back to the old fashioned way of manually writing SQL. At best, ChatGPT is a sometimes useful co-pilot for analysts to get syntax right.
**But there’s hope!** We’ve spent the last few months immersed in this problem, trying various models, techniques and approaches to improve the accuracy of SQL generated by LLMs. In this paper, we show the performance of various LLMs and how the strategy of providing contextually relevant correct SQL to the LLM can allow the LLM to **achieve extremely high accuracy**.
## Setting up architecture of the test
First, we needed to define the architecture of the test. A rough outline is below, in a five step process, with _pseudo code_ below -
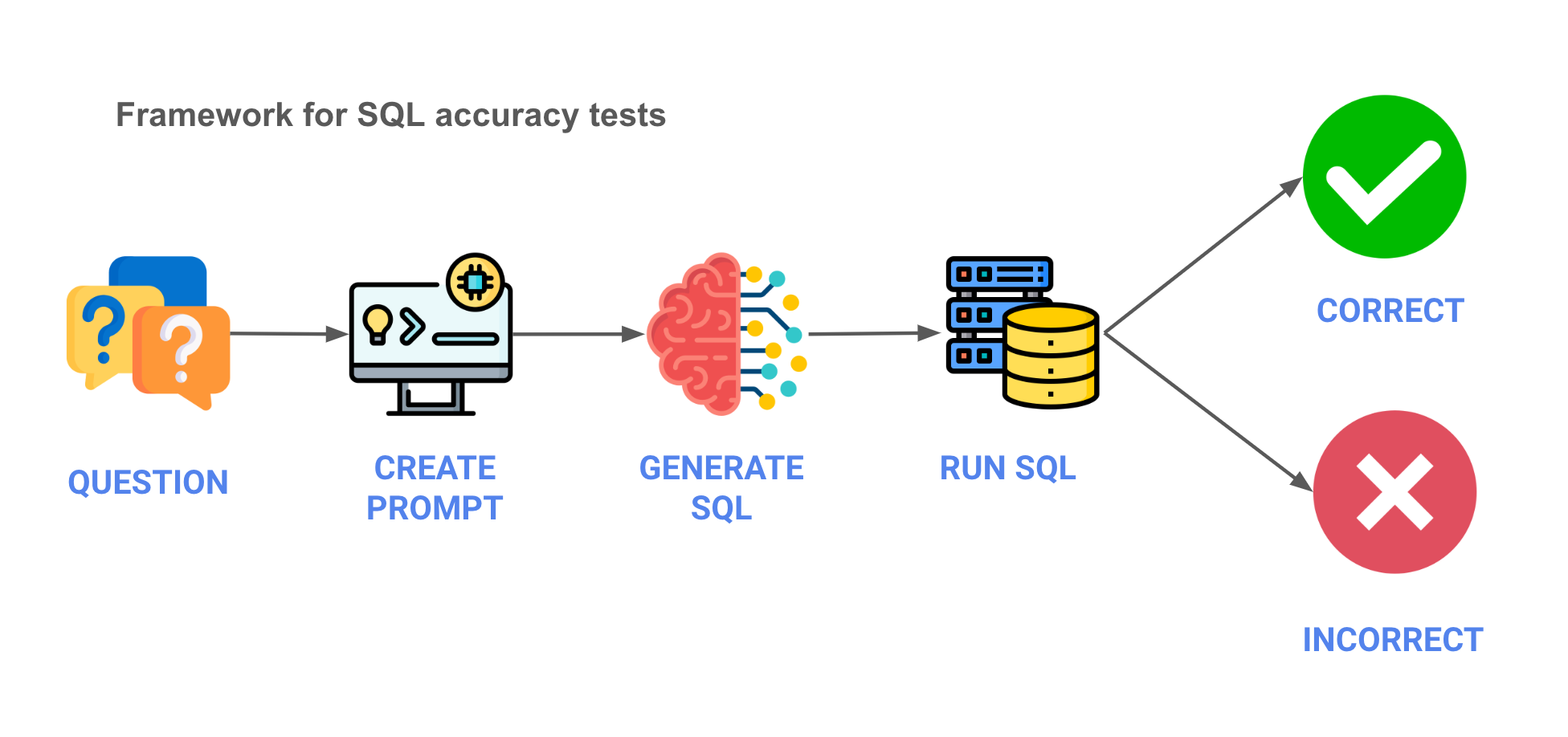
1. **Question** - We start with the business question.
```python
question = "how many clients are there in germany"
```
2. **Prompt** - We create the prompt to send to the LLM.
```python
prompt = f"""
Write a SQL statement for the following question:
{question}
"""
```
3. **Generate SQL** - Using an API, we’ll send the prompt to the LLM and get back generated SQL.
```python
sql = llm.api(api_key=api_key, prompt=prompt, parameters=parameters)
```
4. **Run SQL** - We'll run the SQL against the database.
```python
df = db.conn.execute(sql)
```
5. **Validate results** - Finally, we’ll validate that the results are in line with what we expect.
There are some shades of grey when it comes to the results so we did a manual evaluation of the results. You can see those results [here](https://github.com/vanna-ai/research/blob/main/data/sec_evaluation_data_tagged.csv)
## Setting up the test levers
Now that we have our experiment set up, we’ll need to figure out what levers would impact accuracy, and what our test set would be. We tried two levers (the LLMs and the training data used), and we ran on 20 questions that made up our test set. So we ran a total of 3 LLMs x 3 context strategies x 20 questions = 180 individual trials in this experiment.
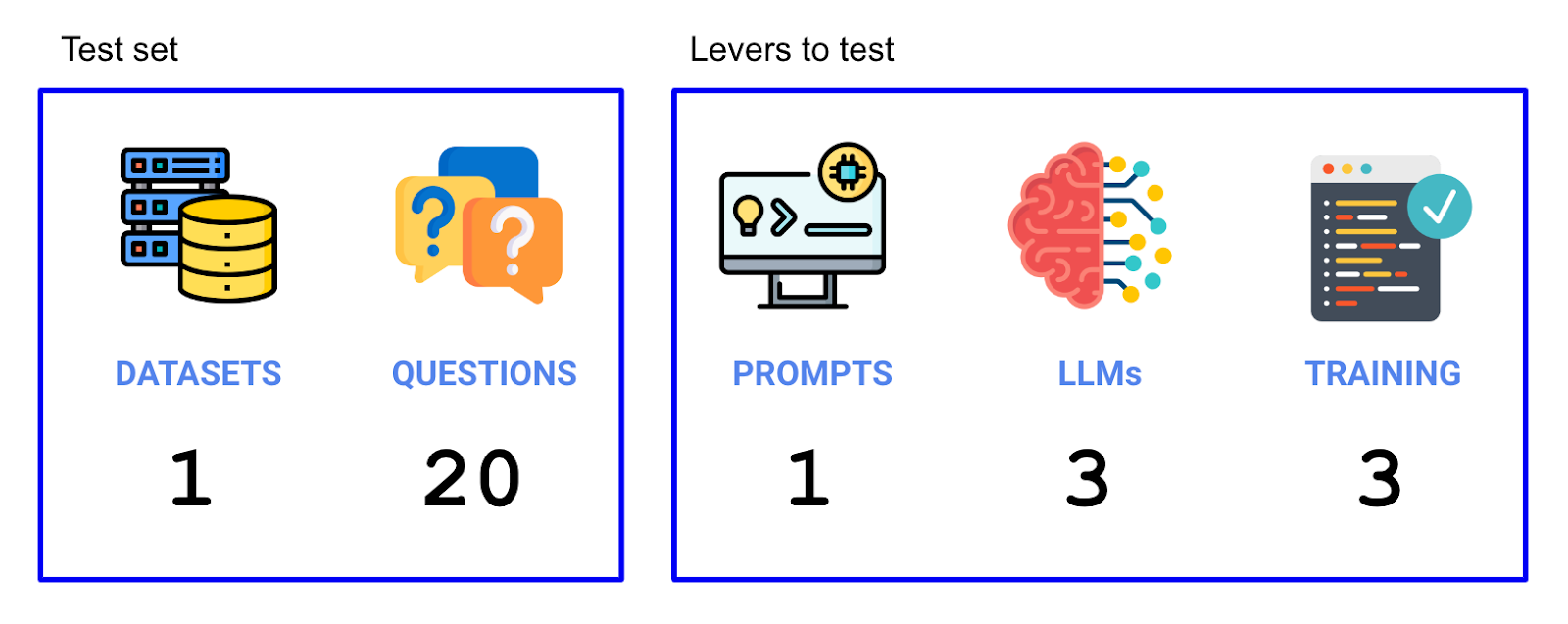
### Choosing a dataset
First, we need to **choose an appropriate dataset** to try. We had a few guiding principles -
1. **Representative**. Datasets in enterprises are often complex and this complexity isn’t captured in many demo / sample datasets. We want to use a complicated database that has real-word use cases that contains real-world data.
2. **Accessible**. We also wanted that dataset to be publicly available.
3. **Understandable**. The dataset should be somewhat understandable to a wide audience - anything too niche or technical would be difficult to decipher.
4. **Maintained**. We’d prefer a dataset that’s maintained and updated properly, in reflection of a real database.
A dataset that we found that met the criteria above was the Cybersyn SEC filings dataset, which is available for free on the Snowflake marketplace:
https://docs.cybersyn.com/our-data-products/economic-and-financial/sec-filings
### Choosing the questions
Next, we need to **choose the questions**. Here are some sample questions (see them all in this [file](https://github.com/vanna-ai/research/blob/main/data/questions_sec.csv)) -
1. How many companies are there in the dataset?
2. What annual measures are available from the 'ALPHABET INC.' Income Statement?
3. What are the quarterly 'Automotive sales' and 'Automotive leasing' for Tesla?
4. How many Chipotle restaurants are there currently?
Now that we have the dataset + questions, we’ll need to come up with the levers.
### Choosing the prompt
For the **prompt**, for this run, we are going to hold the prompt constant, though we’ll do a follow up which varies the prompt.
### Choosing the LLMs (Foundational models)
For the **LLMs** to test, we’ll try the following -
1. [**Bison (Google)**](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/models) - Bison is the version of [PaLM 2](https://blog.google/technology/ai/google-palm-2-ai-large-language-model/) that’s available via GCP APIs.
2. [**GPT 3.5 Turbo (OpenAI)**](https://platform.openai.com/docs/models/gpt-3-5) - GPT 3.5 until recently was the flagship OpenAI model despite 4 being available because of latency and cost benefits, and not a huge accuracy difference (well - we’ll put that to the test) especially for basic tasks.
3. [**GPT 4 (OpenAI)**](https://platform.openai.com/docs/models/gpt-4) - The more advanced but less performant OpenAI model. GPT 4 is multi-modal, though we won’t be using that functionality.
4. [**Llama 2 (Meta)**](https://ai.meta.com/llama/) - We really wanted to include an open source model - and the leading one is Meta’s Llama 2. But our setup through [Replicate](https://replicate.com/replicate/llama-2-70b-chat) quickly conked out, and we weren’t able to fix it in time for publishing this. In our early runs, when it did work, we found performance to be mediocre at best.
### Choosing the context
Finally, we’ll have three types of **context**. Context refers to what we send to the LLM that helps give the LLM context on our specific dataset.
1. **Schema only**. We put the schema (using DDL) in the context window.
2. **Static examples**. We put static example SQL queries in the context windows.
3. **Contextually relevant examples**. Finally, we put the most relevant context (SQL / DDL / documentation) into the context window, finding it via a vector search based on embeddings.
## Using ChatGPT to generate SQL
This section is a bit unfair to ChatGPT, but it’s a helpful place to get started. Let’s just take a question and ask ChatGPT to generate the SQL -
**Prompt**
```
Write Snowflake SQL to answer the following question -
What are the quarterly revenues by business segment for Alphabet?
Return SQL only
```
**Response**
Certainly, here's the SQL query:
```sql
SELECT
EXTRACT(QUARTER FROM date_column) AS quarter,
business_segment,
SUM(revenue) AS quarterly_revenue
FROM
revenue_table
WHERE
company_name = 'Alphabet'
GROUP BY
quarter,
business_segment
ORDER BY
quarter,
business_segment;
-- Replace date_column, business_segment, revenue, revenue_table, and adjust any other identifiers to match your specific database schema.
```
Inevitably, when we try to run this, we hit an error, because it made up the table name since we didn't provide it -

Of course, we are being unfair to the LLMs - as magical as they are, they cannot (unfortunately? luckily?) possibly know what’s in our database - yet. So let’s hop into the tests where we give more context.
## Using schema only
First, we take the schema of the dataset and put it into the context window. This is usually what we've seen people do with ChatGPT or in tutorials.
An example prompt may look like this (in reality we used the information schema because of how Snowflake shares work but this shows the principle) -
```
The user provides a question and you provide SQL. You will only respond with SQL code and not with any explanations.
Respond with only SQL code. Do not answer with any explanations -- just the code.
You may use the following DDL statements as a reference for what tables might be available.
CREATE TABLE Table1...
CREATE TABLE Table2...
CREATE TABLE Table3...
```
The results were, in a word, terrible. Of the 60 attempts (20 questions x 3 models), only two questions were answered correctly (both by GPT 4), **for an abysmal accuracy rate of 3%**. Here are the two questions that GPT 4 managed to get right -
1. What are the top 10 measure descriptions by frequency?
2. What are the distinct statements in the report attributes?
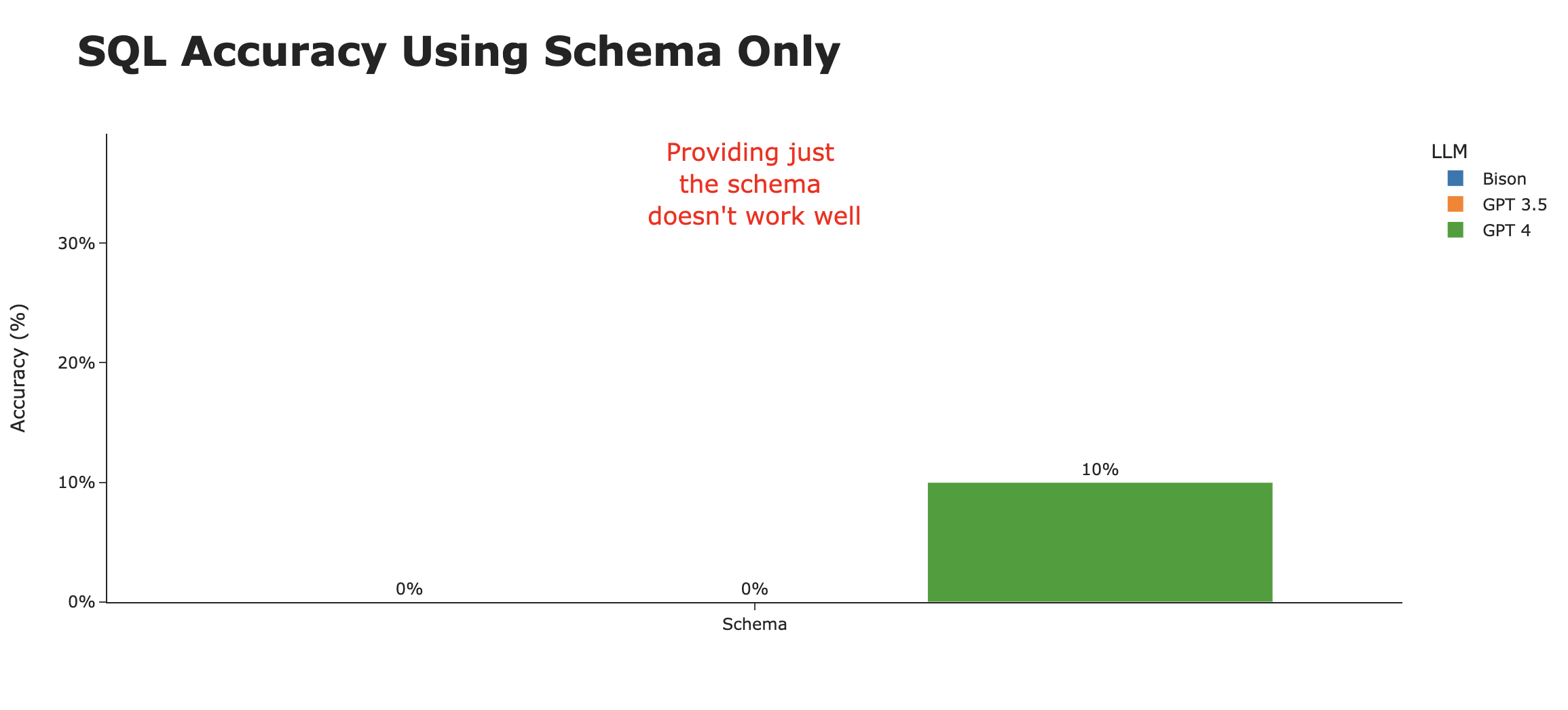
It’s evident that by just using the schema, we don’t get close to meeting the bar of a helpful AI SQL agent, though it may be somewhat useful in being an analyst copilot.
## Using SQL examples
If we put ourselves in the shoes of a human who’s exposed to this dataset for the first time, in addition to the table definitions, they’d first look at the example queries to see _how_ to query the database correctly.
These queries can give additional context not available in the schema - for example, which columns to use, how tables join together, and other intricacies of querying that particular dataset.
Cybersyn, as with other data providers on the Snowflake marketplace, provides a few (in this case 3) example queries in their documentation. Let’s include these in the context window.
By providing just those 3 example queries, we see substantial improvements to the correctness of the SQL generated. However, this accuracy greatly varies by the underlying LLM. It seems that GPT-4 is the most able to generalize the example queries in a way that generates the most accurate SQL.
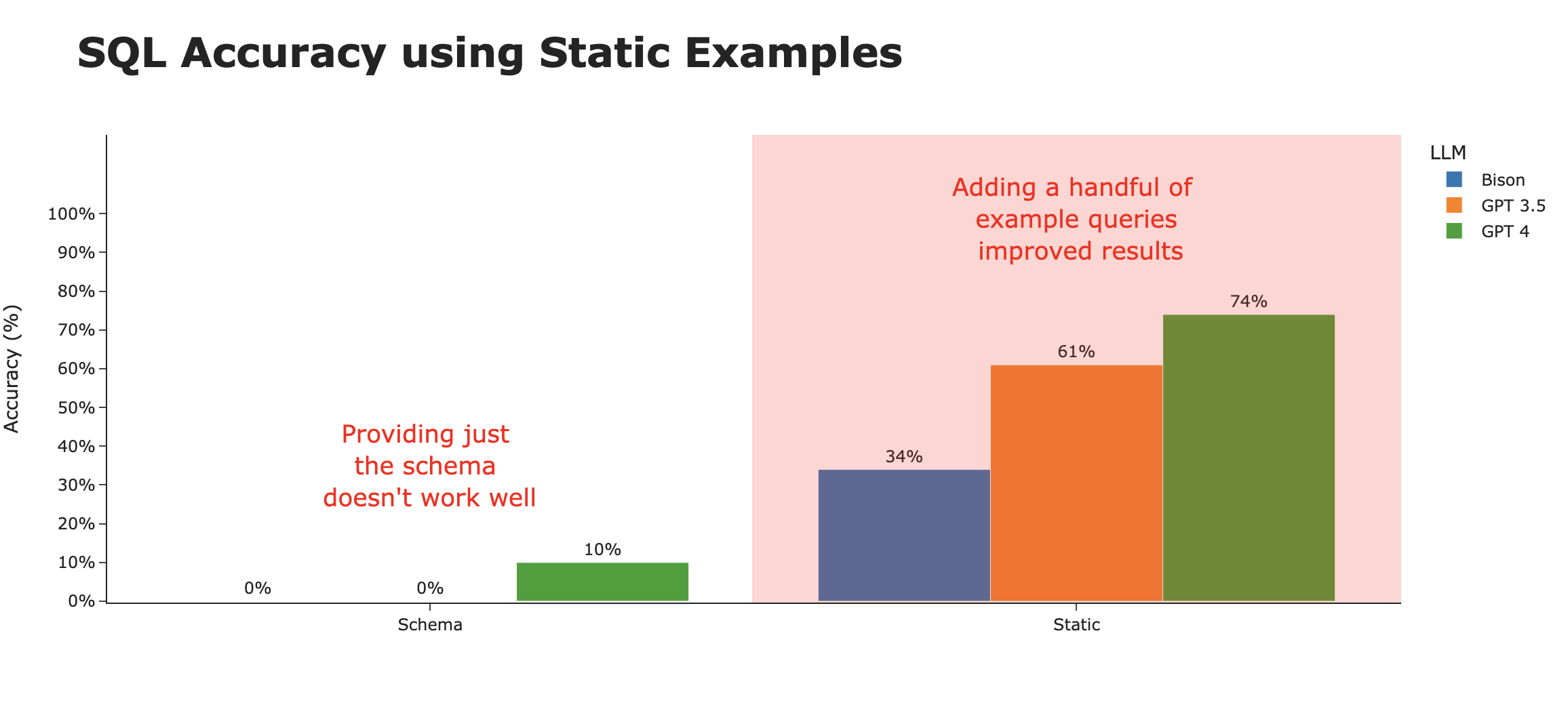
## Using contextually relevant examples
Enterprise data warehouses often contain 100s (or even 1000s) of tables, and an order of magnitude more queries that cover all the use cases within their organizations. Given the limited size of the context windows of modern LLMs, we can’t just shove all the prior queries and schema definitions into the prompt.
Our final approach to context is a more sophisticated ML approach - load embeddings of prior queries and the table schemas into a vector database, and only choose the most relevant queries / tables to the question asked. Here's a diagram of what we are doing - note the contextual relevance search in the green box -
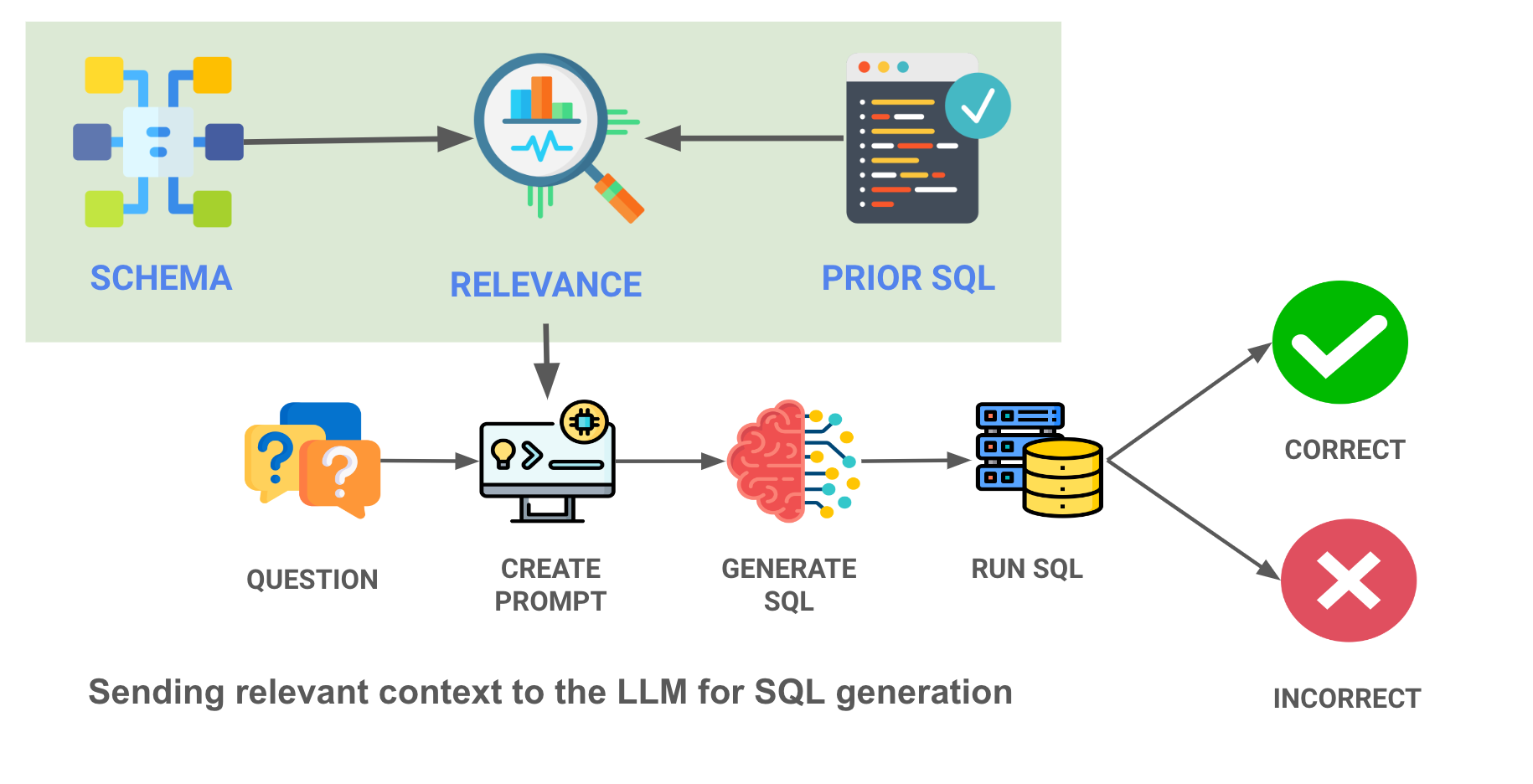
By surfacing the most relevant examples of those SQL queries to the LLM, we can drastically improve performance of even the less capable LLMs. Here, we give the LLM the 10 most relevant SQL query examples for the question (from a list of 30 examples stored), and accuracy rates skyrocket.
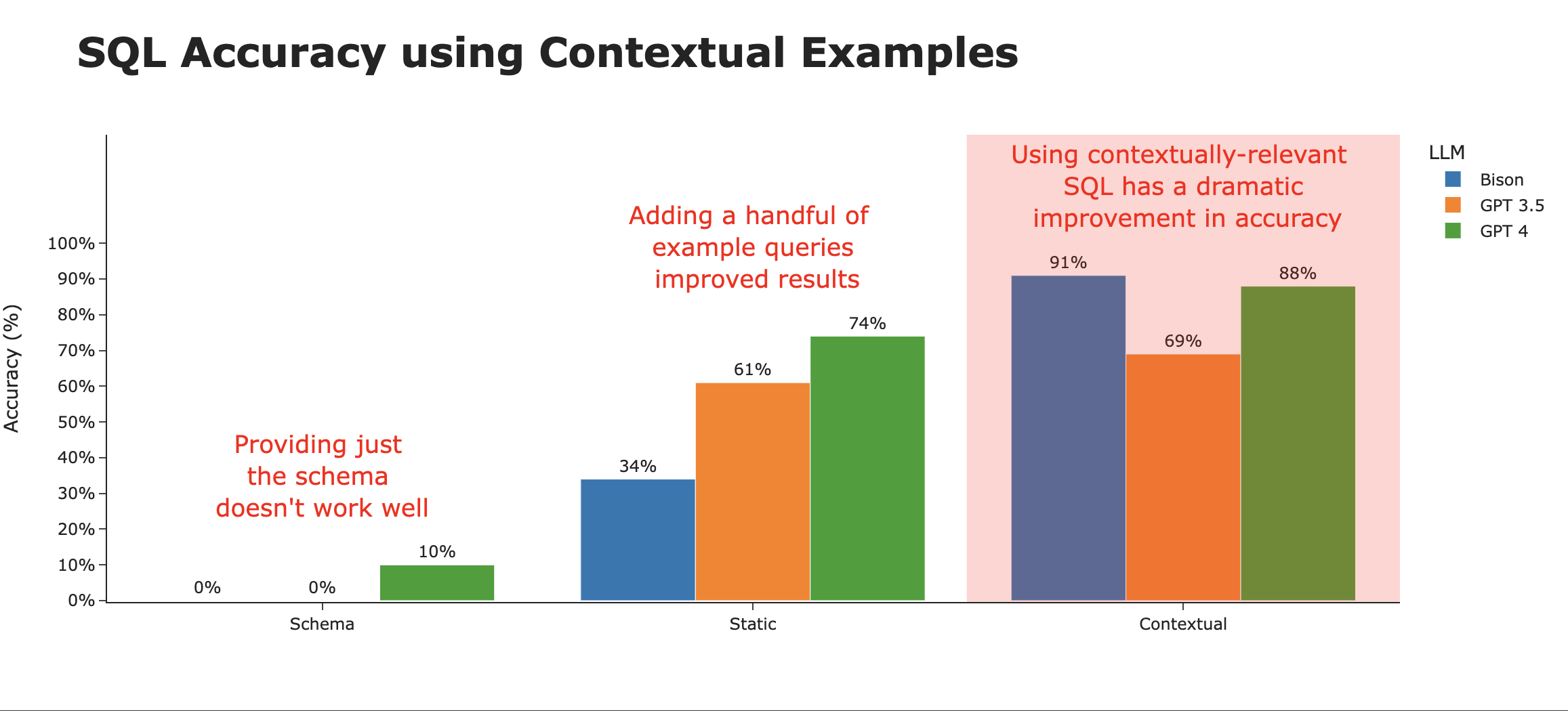
We can improve performance even more by maintaining a history of SQL statements that were executable and correctly answer actual questions that users have had.
## Analyzing the results
It’s clear that the biggest difference is not in the type of LLM, but rather in the strategy employed to give the appropriate context to the LLM (eg the “training data” used).

When looking at SQL accuracy by context strategy, it’s clear that this is what makes the difference. We go from ~3% accurate using just the schema, to ~80% accurate when intelligently using contextual examples.

There are still interesting trends with the LLMs themselves. While Bison starts out at the bottom of the heap in both the Schema and Static context strategies, it rockets to the top with a full Contextual strategy. Averaged across the three strategies, **GPT 4 takes the crown as the best LLM for SQL generation**.
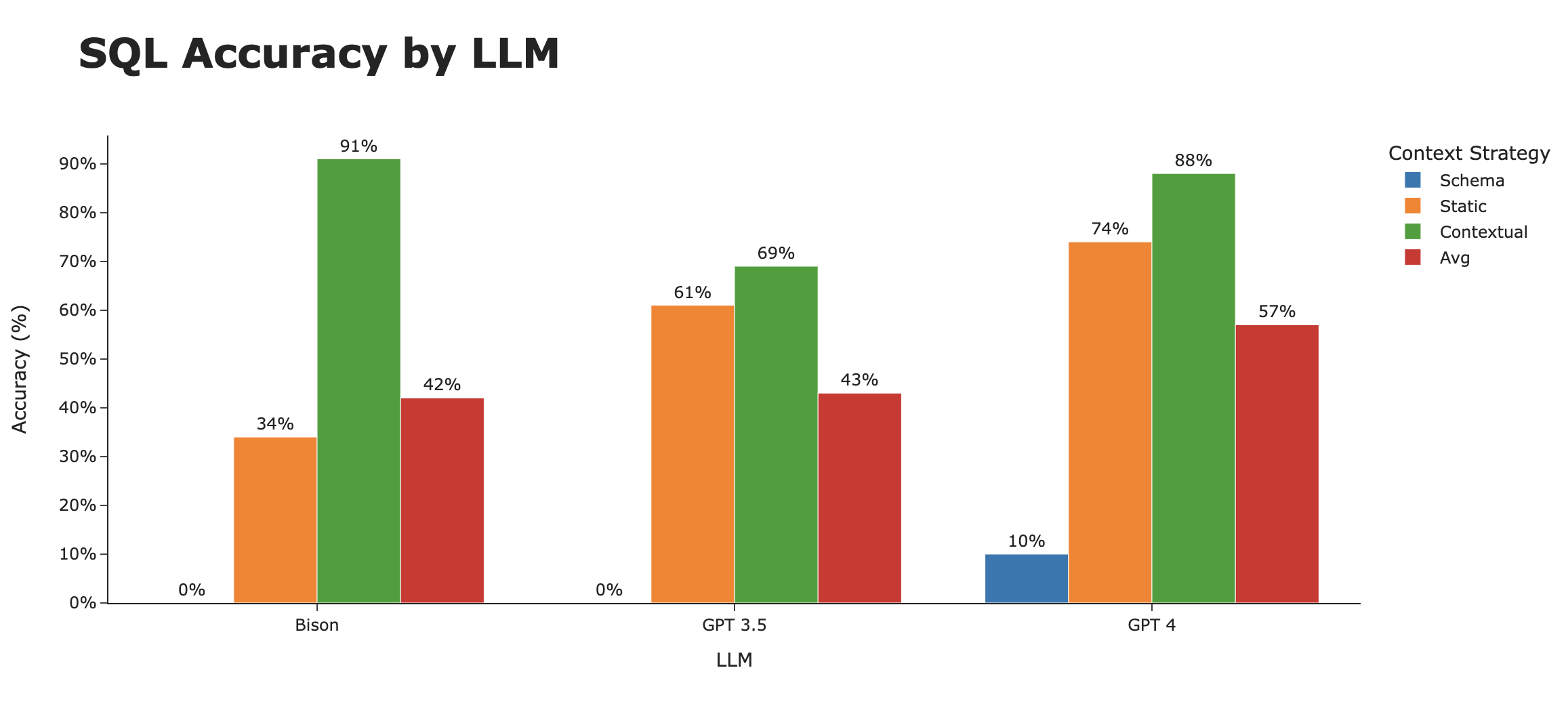
## Next steps to getting accuracy even higher
We'll soon do a follow up on this analysis to get even deeper into accurate SQL generation. Some next steps are -
1. **Use other datasets**: We'd love to try this on other, real world, enterprise datasets. What happens when you get to 100 tables? 1000 tables?
2. **Add more training data**: While 30 queries is great, what happens when you 10x, 100x that number?
3. **Try more databases**: This test was run on a Snowflake database, but we've also gotten this working on BigQuery, Postgres, Redshift, and SQL Server.
4. **Experiment with more foundational models:** We are close to being able to use Llama 2, and we'd love to try other LLMs.
We have some anecdotal evidence for the above but we'll be expanding and refining our tests to include more of these items.
## Use AI to write SQL for your dataset
While the SEC data is a good start, you must be wondering whether this could be relevant for your data and your organization. We’re building a [Python package](https://vanna.ai) that can generate SQL for your database as well as additional functionality like being able to generate Plotly code for the charts, follow-up questions, and various other functions.
Here's an overview of how it works
```python
import vanna as vn
```
1. **Train Using Schema**
```python
vn.train(ddl="CREATE TABLE ...")
```
2. **Train Using Documentation**
```python
vn.train(documentation="...")
```
3. **Train Using SQL Examples**
```python
vn.train(sql="SELECT ...")
```
4. **Generating SQL**
The easiest ways to use Vanna out of the box are `vn.ask(question="What are the ...")` which will return the SQL, table, and chart as you can see in this [example notebook](https://vanna.ai/docs/getting-started.html). `vn.ask` is a wrapper around `vn.generate_sql`, `vn.run_sql`, `vn.generate_plotly_code`, `vn.get_plotly_figure`, and `vn.generate_followup_questions`. This will use optimized context to generate SQL for your question where Vanna will call the LLM for you.
Alternately, you can use `vn.get_related_training_data(question="What are the ...")` as shown in this [notebook](https://github.com/vanna-ai/research/blob/main/notebooks/test-cybersyn-sec.ipynb) which will retrieve the most relevant context that you can use to construct your own prompt to send to any LLM.
This [notebook](https://github.com/vanna-ai/research/blob/main/notebooks/train-cybersyn-sec-3.ipynb) shows an example of how the "Static" context strategy was used to train Vanna on the Cybersyn SEC dataset.
## A note on nomenclature
* **Foundational Model**: This is the underlying LLM
* **Context Model (aka Vanna Model)**: This is a layer that sits on top of the LLM and provides context to the LLM
* **Training**: Generally when we refer to "training" we're talking about training the context model.
## Contact Us
Ping us on [Slack](https://join.slack.com/t/vanna-ai/shared_invite/zt-1unu0ipog-iE33QCoimQiBDxf2o7h97w), [Discord](https://discord.com/invite/qUZYKHremx), or [set up a 1:1 call](https://calendly.com/d/y7j-yqq-yz4/meet-with-both-vanna-co-founders) if you have any issues.
## /papers/img/accuracy-by-llm.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/accuracy-by-llm.png
## /papers/img/accuracy-using-contextual-examples.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/accuracy-using-contextual-examples.png
## /papers/img/accuracy-using-schema-only.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/accuracy-using-schema-only.png
## /papers/img/accuracy-using-static-examples.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/accuracy-using-static-examples.png
## /papers/img/chat-gpt-question.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/chat-gpt-question.png
## /papers/img/chatgpt-results.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/chatgpt-results.png
## /papers/img/framework-for-sql-generation.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/framework-for-sql-generation.png
## /papers/img/question-flow.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/question-flow.png
## /papers/img/schema-only.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/schema-only.png
## /papers/img/sql-error.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/sql-error.png
## /papers/img/summary-table.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/summary-table.png
## /papers/img/summary.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/summary.png
## /papers/img/test-architecture.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/test-architecture.png
## /papers/img/test-levers.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/test-levers.png
## /papers/img/using-contextually-relevant-examples.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/using-contextually-relevant-examples.png
## /papers/img/using-sql-examples.png
Binary file available at https://raw.githubusercontent.com/vanna-ai/vanna/refs/heads/main/papers/img/using-sql-examples.png
## /pyproject.toml
```toml path="/pyproject.toml"
[build-system]
requires = ["flit_core >=3.2,<4"]
build-backend = "flit_core.buildapi"
[project]
name = "vanna"
version = "0.7.9"
authors = [
{ name="Zain Hoda", email="zain@vanna.ai" },
]
description = "Generate SQL queries from natural language"
readme = "README.md"
requires-python = ">=3.9"
classifiers = [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
]
dependencies = [
"requests", "tabulate", "plotly", "pandas", "sqlparse", "kaleido", "flask", "flask-sock", "flasgger", "sqlalchemy"
]
[project.urls]
"Homepage" = "https://github.com/vanna-ai/vanna"
"Bug Tracker" = "https://github.com/vanna-ai/vanna/issues"
[project.optional-dependencies]
postgres = ["psycopg2-binary", "db-dtypes"]
mysql = ["PyMySQL"]
clickhouse = ["clickhouse_connect"]
bigquery = ["google-cloud-bigquery"]
snowflake = ["snowflake-connector-python"]
duckdb = ["duckdb"]
google = ["google-generativeai", "google-cloud-aiplatform"]
all = ["psycopg2-binary", "db-dtypes", "PyMySQL", "google-cloud-bigquery", "snowflake-connector-python", "duckdb", "openai", "qianfan", "mistralai>=1.0.0", "chromadb<1.0.0", "anthropic", "zhipuai", "marqo", "google-generativeai", "google-cloud-aiplatform", "qdrant-client", "fastembed", "ollama", "httpx", "opensearch-py", "opensearch-dsl", "transformers", "pinecone", "pymilvus[model]","weaviate-client", "azure-search-documents", "azure-identity", "azure-common", "faiss-cpu", "boto", "boto3", "botocore", "langchain_core", "langchain_postgres", "langchain-community", "langchain-huggingface", "xinference-client"]
test = ["tox"]
chromadb = ["chromadb<1.0.0"]
openai = ["openai"]
qianfan = ["qianfan"]
mistralai = ["mistralai>=1.0.0"]
anthropic = ["anthropic"]
gemini = ["google-generativeai"]
marqo = ["marqo"]
zhipuai = ["zhipuai"]
ollama = ["ollama", "httpx"]
qdrant = ["qdrant-client", "fastembed"]
vllm = ["vllm"]
pinecone = ["pinecone", "fastembed"]
opensearch = ["opensearch-py", "opensearch-dsl", "langchain-community", "langchain-huggingface"]
hf = ["transformers"]
milvus = ["pymilvus[model]"]
bedrock = ["boto3", "botocore"]
weaviate = ["weaviate-client"]
azuresearch = ["azure-search-documents", "azure-identity", "azure-common", "fastembed"]
pgvector = ["langchain-postgres>=0.0.12"]
faiss-cpu = ["faiss-cpu"]
faiss-gpu = ["faiss-gpu"]
xinference-client = ["xinference-client"]
oracle = ["oracledb", "chromadb<1.0.0"]
```
## /setup.cfg
```cfg path="/setup.cfg"
[flake8]
ignore = BLK100,W503,E203,E722,F821,F841
max-line-length = 100
exclude = .tox,.git,docs,venv,jupyter_notebook_config.py,jupyter_lab_config.py,assets.py
[tool:brunette]
verbose = true
single-quotes = false
target-version = py39
exclude = .tox,.git,docs,venv,assets.py
```
## /src/.editorconfig
```editorconfig path="/src/.editorconfig"
# top-most EditorConfig file
root = true
# Python files
[*.py]
# Indentation style: space
indent_style = space
# Indentation size: Use 2 spaces
indent_size = 2
# Newline character at the end of file
insert_final_newline = true
# Charset: utf-8
charset = utf-8
# Trim trailing whitespace
trim_trailing_whitespace = true
# Max line length: 79 characters as per PEP 8 guidelines
max_line_length = 79
# Set end of line format to LF
# Exclude specific files or directories
exclude = 'docs|node_modules|migrations|.git|.tox'
```
## /src/vanna/ZhipuAI/ZhipuAI_Chat.py
```py path="/src/vanna/ZhipuAI/ZhipuAI_Chat.py"
import re
from typing import List
import pandas as pd
from zhipuai import ZhipuAI
from ..base import VannaBase
class ZhipuAI_Chat(VannaBase):
def __init__(self, config=None):
VannaBase.__init__(self, config=config)
if config is None:
return
if "api_key" not in config:
raise Exception("Missing api_key in config")
self.api_key = config["api_key"]
self.model = config["model"] if "model" in config else "glm-4"
self.api_url = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
# Static methods similar to those in ZhipuAI_Chat for message formatting and utility
@staticmethod
def system_message(message: str) -> dict:
return {"role": "system", "content": message}
@staticmethod
def user_message(message: str) -> dict:
return {"role": "user", "content": message}
@staticmethod
def assistant_message(message: str) -> dict:
return {"role": "assistant", "content": message}
@staticmethod
def str_to_approx_token_count(string: str) -> int:
return len(string) / 4
@staticmethod
def add_ddl_to_prompt(
initial_prompt: str, ddl_list: List[str], max_tokens: int = 14000
) -> str:
if len(ddl_list) > 0:
initial_prompt += "\nYou may use the following DDL statements as a reference for what tables might be available. Use responses to past questions also to guide you:\n\n"
for ddl in ddl_list:
if (
ZhipuAI_Chat.str_to_approx_token_count(initial_prompt)
+ ZhipuAI_Chat.str_to_approx_token_count(ddl)
< max_tokens
):
initial_prompt += f"{ddl}\n\n"
return initial_prompt
@staticmethod
def add_documentation_to_prompt(
initial_prompt: str, documentation_List: List[str], max_tokens: int = 14000
) -> str:
if len(documentation_List) > 0:
initial_prompt += "\nYou may use the following documentation as a reference for what tables might be available. Use responses to past questions also to guide you:\n\n"
for documentation in documentation_List:
if (
ZhipuAI_Chat.str_to_approx_token_count(initial_prompt)
+ ZhipuAI_Chat.str_to_approx_token_count(documentation)
< max_tokens
):
initial_prompt += f"{documentation}\n\n"
return initial_prompt
@staticmethod
def add_sql_to_prompt(
initial_prompt: str, sql_List: List[str], max_tokens: int = 14000
) -> str:
if len(sql_List) > 0:
initial_prompt += "\nYou may use the following SQL statements as a reference for what tables might be available. Use responses to past questions also to guide you:\n\n"
for question in sql_List:
if (
ZhipuAI_Chat.str_to_approx_token_count(initial_prompt)
+ ZhipuAI_Chat.str_to_approx_token_count(question["sql"])
< max_tokens
):
initial_prompt += f"{question['question']}\n{question['sql']}\n\n"
return initial_prompt
def get_sql_prompt(
self,
question: str,
question_sql_list: List,
ddl_list: List,
doc_list: List,
**kwargs,
):
initial_prompt = "The user provides a question and you provide SQL. You will only respond with SQL code and not with any explanations.\n\nRespond with only SQL code. Do not answer with any explanations -- just the code.\n"
initial_prompt = ZhipuAI_Chat.add_ddl_to_prompt(
initial_prompt, ddl_list, max_tokens=14000
)
initial_prompt = ZhipuAI_Chat.add_documentation_to_prompt(
initial_prompt, doc_list, max_tokens=14000
)
message_log = [ZhipuAI_Chat.system_message(initial_prompt)]
for example in question_sql_list:
if example is None:
print("example is None")
else:
if example is not None and "question" in example and "sql" in example:
message_log.append(ZhipuAI_Chat.user_message(example["question"]))
message_log.append(ZhipuAI_Chat.assistant_message(example["sql"]))
message_log.append({"role": "user", "content": question})
return message_log
def get_followup_questions_prompt(
self,
question: str,
df: pd.DataFrame,
question_sql_list: List,
ddl_list: List,
doc_list: List,
**kwargs,
):
initial_prompt = f"The user initially asked the question: '{question}': \n\n"
initial_prompt = ZhipuAI_Chat.add_ddl_to_prompt(
initial_prompt, ddl_list, max_tokens=14000
)
initial_prompt = ZhipuAI_Chat.add_documentation_to_prompt(
initial_prompt, doc_list, max_tokens=14000
)
initial_prompt = ZhipuAI_Chat.add_sql_to_prompt(
initial_prompt, question_sql_list, max_tokens=14000
)
message_log = [ZhipuAI_Chat.system_message(initial_prompt)]
message_log.append(
ZhipuAI_Chat.user_message(
"Generate a List of followup questions that the user might ask about this data. Respond with a List of questions, one per line. Do not answer with any explanations -- just the questions."
)
)
return message_log
def generate_question(self, sql: str, **kwargs) -> str:
response = self.submit_prompt(
[
self.system_message(
"The user will give you SQL and you will try to guess what the business question this query is answering. Return just the question without any additional explanation. Do not reference the table name in the question."
),
self.user_message(sql),
],
**kwargs,
)
return response
def _extract_python_code(self, markdown_string: str) -> str:
# Regex pattern to match Python code blocks
pattern = r"\`\`\`[\w\s]*python\n([\s\S]*?)\`\`\`|\`\`\`([\s\S]*?)\`\`\`"
# Find all matches in the markdown string
matches = re.findall(pattern, markdown_string, re.IGNORECASE)
# Extract the Python code from the matches
python_code = []
for match in matches:
python = match[0] if match[0] else match[1]
python_code.append(python.strip())
if len(python_code) == 0:
return markdown_string
return python_code[0]
def _sanitize_plotly_code(self, raw_plotly_code: str) -> str:
# Remove the fig.show() statement from the plotly code
plotly_code = raw_plotly_code.replace("fig.show()", "")
return plotly_code
def generate_plotly_code(
self, question: str = None, sql: str = None, df_metadata: str = None, **kwargs
) -> str:
if question is not None:
system_msg = f"The following is a pandas DataFrame that contains the results of the query that answers the question the user asked: '{question}'"
else:
system_msg = "The following is a pandas DataFrame "
if sql is not None:
system_msg += f"\n\nThe DataFrame was produced using this query: {sql}\n\n"
system_msg += f"The following is information about the resulting pandas DataFrame 'df': \n{df_metadata}"
message_log = [
self.system_message(system_msg),
self.user_message(
"Can you generate the Python plotly code to chart the results of the dataframe? Assume the data is in a pandas dataframe called 'df'. If there is only one value in the dataframe, use an Indicator. Respond with only Python code. Do not answer with any explanations -- just the code."
),
]
plotly_code = self.submit_prompt(message_log, kwargs=kwargs)
return self._sanitize_plotly_code(self._extract_python_code(plotly_code))
def submit_prompt(
self, prompt, max_tokens=500, temperature=0.7, top_p=0.7, stop=None, **kwargs
):
if prompt is None:
raise Exception("Prompt is None")
if len(prompt) == 0:
raise Exception("Prompt is empty")
client = ZhipuAI(api_key=self.api_key)
response = client.chat.completions.create(
model="glm-4",
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
stop=stop,
messages=prompt,
)
return response.choices[0].message.content
```
## /src/vanna/ZhipuAI/ZhipuAI_embeddings.py
```py path="/src/vanna/ZhipuAI/ZhipuAI_embeddings.py"
from typing import List
from zhipuai import ZhipuAI
from chromadb import Documents, EmbeddingFunction, Embeddings
from ..base import VannaBase
class ZhipuAI_Embeddings(VannaBase):
"""
[future functionality] This function is used to generate embeddings from ZhipuAI.
Args:
VannaBase (_type_): _description_
"""
def __init__(self, config=None):
VannaBase.__init__(self, config=config)
if "api_key" not in config:
raise Exception("Missing api_key in config")
self.api_key = config["api_key"]
self.client = ZhipuAI(api_key=self.api_key)
def generate_embedding(self, data: str, **kwargs) -> List[float]:
embedding = self.client.embeddings.create(
model="embedding-2",
input=data,
)
return embedding.data[0].embedding
class ZhipuAIEmbeddingFunction(EmbeddingFunction[Documents]):
"""
A embeddingFunction that uses ZhipuAI to generate embeddings which can use in chromadb.
usage:
class MyVanna(ChromaDB_VectorStore, ZhipuAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
ZhipuAI_Chat.__init__(self, config=config)
config={'api_key': 'xxx'}
zhipu_embedding_function = ZhipuAIEmbeddingFunction(config=config)
config = {"api_key": "xxx", "model": "glm-4","path":"xy","embedding_function":zhipu_embedding_function}
vn = MyVanna(config)
"""
def __init__(self, config=None):
if config is None or "api_key" not in config:
raise ValueError("Missing 'api_key' in config")
self.api_key = config["api_key"]
self.model_name = config.get("model_name", "embedding-2")
try:
self.client = ZhipuAI(api_key=self.api_key)
except Exception as e:
raise ValueError(f"Error initializing ZhipuAI client: {e}")
def __call__(self, input: Documents) -> Embeddings:
# Replace newlines, which can negatively affect performance.
input = [t.replace("\n", " ") for t in input]
all_embeddings = []
print(f"Generating embeddings for {len(input)} documents")
# Iterating over each document for individual API calls
for document in input:
try:
response = self.client.embeddings.create(
model=self.model_name,
input=document
)
# print(response)
embedding = response.data[0].embedding
all_embeddings.append(embedding)
# print(f"Cost required: {response.usage.total_tokens}")
except Exception as e:
raise ValueError(f"Error generating embedding for document: {e}")
return all_embeddings
```
## /src/vanna/ZhipuAI/__init__.py
```py path="/src/vanna/ZhipuAI/__init__.py"
from .ZhipuAI_Chat import ZhipuAI_Chat
from .ZhipuAI_embeddings import ZhipuAI_Embeddings, ZhipuAIEmbeddingFunction
```
## /src/vanna/__init__.py
```py path="/src/vanna/__init__.py"
import dataclasses
import json
import os
from dataclasses import dataclass
from typing import Callable, List, Tuple, Union
import pandas as pd
import requests
import plotly.graph_objs
from .exceptions import (
OTPCodeError,
ValidationError,
)
from .types import (
ApiKey,
Status,
TrainingData,
UserEmail,
UserOTP,
)
from .utils import sanitize_model_name, validate_config_path
api_key: Union[str, None] = None # API key for Vanna.AI
fig_as_img: bool = False # Whether or not to return Plotly figures as images
run_sql: Union[
Callable[[str], pd.DataFrame], None
] = None # Function to convert SQL to a Pandas DataFrame
"""
**Example**
\`\`\`python
vn.run_sql = lambda sql: pd.read_sql(sql, engine)
\`\`\`
Set the SQL to DataFrame function for Vanna.AI. This is used in the [`vn.ask(...)`][vanna.ask] function.
Instead of setting this directly you can also use [`vn.connect_to_snowflake(...)`][vanna.connect_to_snowflake] to set this.
"""
__org: Union[str, None] = None # Organization name for Vanna.AI
_unauthenticated_endpoint = "https://ask.vanna.ai/unauthenticated_rpc"
def error_deprecation():
raise Exception("""
Please switch to the following method for initializing Vanna:
from vanna.remote import VannaDefault
api_key = # Your API key from https://vanna.ai/account/profile
vanna_model_name = # Your model name from https://vanna.ai/account/profile
vn = VannaDefault(model=vanna_model_name, api_key=api_key)
""")
def __unauthenticated_rpc_call(method, params):
headers = {
"Content-Type": "application/json",
}
data = {"method": method, "params": [__dataclass_to_dict(obj) for obj in params]}
response = requests.post(
_unauthenticated_endpoint, headers=headers, data=json.dumps(data)
)
return response.json()
def __dataclass_to_dict(obj):
return dataclasses.asdict(obj)
def get_api_key(email: str, otp_code: Union[str, None] = None) -> str:
"""
**Example:**
\`\`\`python
vn.get_api_key(email="my-email@example.com")
\`\`\`
Login to the Vanna.AI API.
Args:
email (str): The email address to login with.
otp_code (Union[str, None]): The OTP code to login with. If None, an OTP code will be sent to the email address.
Returns:
str: The API key.
"""
vanna_api_key = os.environ.get("VANNA_API_KEY", None)
if vanna_api_key is not None:
return vanna_api_key
if email == "my-email@example.com":
raise ValidationError(
"Please replace 'my-email@example.com' with your email address."
)
if otp_code is None:
params = [UserEmail(email=email)]
d = __unauthenticated_rpc_call(method="send_otp", params=params)
if "result" not in d:
raise OTPCodeError("Error sending OTP code.")
status = Status(**d["result"])
if not status.success:
raise OTPCodeError(f"Error sending OTP code: {status.message}")
otp_code = input("Check your email for the code and enter it here: ")
params = [UserOTP(email=email, otp=otp_code)]
d = __unauthenticated_rpc_call(method="verify_otp", params=params)
if "result" not in d:
raise OTPCodeError("Error verifying OTP code.")
key = ApiKey(**d["result"])
if key is None:
raise OTPCodeError("Error verifying OTP code.")
api_key = key.key
return api_key
def set_api_key(key: str) -> None:
error_deprecation()
def get_models() -> List[str]:
error_deprecation()
def create_model(model: str, db_type: str) -> bool:
error_deprecation()
def add_user_to_model(model: str, email: str, is_admin: bool) -> bool:
error_deprecation()
def update_model_visibility(public: bool) -> bool:
error_deprecation()
def set_model(model: str):
error_deprecation()
def add_sql(
question: str, sql: str, tag: Union[str, None] = "Manually Trained"
) -> bool:
error_deprecation()
def add_ddl(ddl: str) -> bool:
error_deprecation()
def add_documentation(documentation: str) -> bool:
error_deprecation()
@dataclass
class TrainingPlanItem:
item_type: str
item_group: str
item_name: str
item_value: str
def __str__(self):
if self.item_type == self.ITEM_TYPE_SQL:
return f"Train on SQL: {self.item_group} {self.item_name}"
elif self.item_type == self.ITEM_TYPE_DDL:
return f"Train on DDL: {self.item_group} {self.item_name}"
elif self.item_type == self.ITEM_TYPE_IS:
return f"Train on Information Schema: {self.item_group} {self.item_name}"
ITEM_TYPE_SQL = "sql"
ITEM_TYPE_DDL = "ddl"
ITEM_TYPE_IS = "is"
class TrainingPlan:
"""
A class representing a training plan. You can see what's in it, and remove items from it that you don't want trained.
**Example:**
\`\`\`python
plan = vn.get_training_plan()
plan.get_summary()
\`\`\`
"""
_plan: List[TrainingPlanItem]
def __init__(self, plan: List[TrainingPlanItem]):
self._plan = plan
def __str__(self):
return "\n".join(self.get_summary())
def __repr__(self):
return self.__str__()
def get_summary(self) -> List[str]:
"""
**Example:**
\`\`\`python
plan = vn.get_training_plan()
plan.get_summary()
\`\`\`
Get a summary of the training plan.
Returns:
List[str]: A list of strings describing the training plan.
"""
return [f"{item}" for item in self._plan]
def remove_item(self, item: str):
"""
**Example:**
\`\`\`python
plan = vn.get_training_plan()
plan.remove_item("Train on SQL: What is the average salary of employees?")
\`\`\`
Remove an item from the training plan.
Args:
item (str): The item to remove.
"""
for plan_item in self._plan:
if str(plan_item) == item:
self._plan.remove(plan_item)
break
def get_training_plan_postgres(
filter_databases: Union[List[str], None] = None,
filter_schemas: Union[List[str], None] = None,
include_information_schema: bool = False,
use_historical_queries: bool = True,
) -> TrainingPlan:
error_deprecation()
def get_training_plan_generic(df) -> TrainingPlan:
error_deprecation()
def get_training_plan_experimental(
filter_databases: Union[List[str], None] = None,
filter_schemas: Union[List[str], None] = None,
include_information_schema: bool = False,
use_historical_queries: bool = True,
) -> TrainingPlan:
error_deprecation()
def train(
question: str = None,
sql: str = None,
ddl: str = None,
documentation: str = None,
json_file: str = None,
sql_file: str = None,
plan: TrainingPlan = None,
) -> bool:
error_deprecation()
def flag_sql_for_review(
question: str, sql: Union[str, None] = None, error_msg: Union[str, None] = None
) -> bool:
error_deprecation()
def remove_sql(question: str) -> bool:
error_deprecation()
def remove_training_data(id: str) -> bool:
error_deprecation()
def generate_sql(question: str) -> str:
error_deprecation()
def get_related_training_data(question: str) -> TrainingData:
error_deprecation()
def generate_meta(question: str) -> str:
error_deprecation()
def generate_followup_questions(question: str, df: pd.DataFrame) -> List[str]:
error_deprecation()
def generate_questions() -> List[str]:
error_deprecation()
def ask(
question: Union[str, None] = None,
print_results: bool = True,
auto_train: bool = True,
generate_followups: bool = True,
) -> Union[
Tuple[
Union[str, None],
Union[pd.DataFrame, None],
Union[plotly.graph_objs.Figure, None],
Union[List[str], None],
],
None,
]:
error_deprecation()
def generate_plotly_code(
question: Union[str, None],
sql: Union[str, None],
df: pd.DataFrame,
chart_instructions: Union[str, None] = None,
) -> str:
error_deprecation()
def get_plotly_figure(
plotly_code: str, df: pd.DataFrame, dark_mode: bool = True
) -> plotly.graph_objs.Figure:
error_deprecation()
def get_results(cs, default_database: str, sql: str) -> pd.DataFrame:
error_deprecation()
def generate_explanation(sql: str) -> str:
error_deprecation()
def generate_question(sql: str) -> str:
error_deprecation()
def get_all_questions() -> pd.DataFrame:
error_deprecation()
def get_training_data() -> pd.DataFrame:
error_deprecation()
def connect_to_sqlite(url: str):
error_deprecation()
def connect_to_snowflake(
account: str,
username: str,
password: str,
database: str,
schema: Union[str, None] = None,
role: Union[str, None] = None,
):
error_deprecation()
def connect_to_postgres(
host: str = None,
dbname: str = None,
user: str = None,
password: str = None,
port: int = None,
):
error_deprecation()
def connect_to_bigquery(cred_file_path: str = None, project_id: str = None):
error_deprecation()
def connect_to_duckdb(url: str="memory", init_sql: str = None):
error_deprecation()
```
## /src/vanna/advanced/__init__.py
```py path="/src/vanna/advanced/__init__.py"
from abc import ABC, abstractmethod
class VannaAdvanced(ABC):
def __init__(self, config=None):
self.config = config
@abstractmethod
def get_function(self, question: str, additional_data: dict = {}) -> dict:
pass
@abstractmethod
def create_function(self, question: str, sql: str, plotly_code: str, **kwargs) -> dict:
pass
@abstractmethod
def update_function(self, old_function_name: str, updated_function: dict) -> bool:
pass
@abstractmethod
def delete_function(self, function_name: str) -> bool:
pass
@abstractmethod
def get_all_functions(self) -> list:
pass
```
## /src/vanna/anthropic/__init__.py
```py path="/src/vanna/anthropic/__init__.py"
from .anthropic_chat import Anthropic_Chat
```
## /src/vanna/anthropic/anthropic_chat.py
```py path="/src/vanna/anthropic/anthropic_chat.py"
import os
import anthropic
from ..base import VannaBase
class Anthropic_Chat(VannaBase):
def __init__(self, client=None, config=None):
VannaBase.__init__(self, config=config)
# default parameters - can be overrided using config
self.temperature = 0.7
self.max_tokens = 500
if "temperature" in config:
self.temperature = config["temperature"]
if "max_tokens" in config:
self.max_tokens = config["max_tokens"]
if client is not None:
self.client = client
return
if config is None and client is None:
self.client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
return
if "api_key" in config:
self.client = anthropic.Anthropic(api_key=config["api_key"])
def system_message(self, message: str) -> any:
return {"role": "system", "content": message}
def user_message(self, message: str) -> any:
return {"role": "user", "content": message}
def assistant_message(self, message: str) -> any:
return {"role": "assistant", "content": message}
def submit_prompt(self, prompt, **kwargs) -> str:
if prompt is None:
raise Exception("Prompt is None")
if len(prompt) == 0:
raise Exception("Prompt is empty")
# Count the number of tokens in the message log
# Use 4 as an approximation for the number of characters per token
num_tokens = 0
for message in prompt:
num_tokens += len(message["content"]) / 4
if self.config is not None and "model" in self.config:
print(
f"Using model {self.config['model']} for {num_tokens} tokens (approx)"
)
# claude required system message is a single filed
# https://docs.anthropic.com/claude/reference/messages_post
system_message = ''
no_system_prompt = []
for prompt_message in prompt:
role = prompt_message['role']
if role == 'system':
system_message = prompt_message['content']
else:
no_system_prompt.append({"role": role, "content": prompt_message['content']})
response = self.client.messages.create(
model=self.config["model"],
messages=no_system_prompt,
system=system_message,
max_tokens=self.max_tokens,
temperature=self.temperature,
)
return response.content[0].text
```
## /src/vanna/azuresearch/__init__.py
```py path="/src/vanna/azuresearch/__init__.py"
from .azuresearch_vector import AzureAISearch_VectorStore
```
## /src/vanna/azuresearch/azuresearch_vector.py
```py path="/src/vanna/azuresearch/azuresearch_vector.py"
import ast
import json
from typing import List
import pandas as pd
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import (
ExhaustiveKnnAlgorithmConfiguration,
ExhaustiveKnnParameters,
SearchableField,
SearchField,
SearchFieldDataType,
SearchIndex,
VectorSearch,
VectorSearchAlgorithmKind,
VectorSearchAlgorithmMetric,
VectorSearchProfile,
)
from azure.search.documents.models import VectorFilterMode, VectorizedQuery
from fastembed import TextEmbedding
from ..base import VannaBase
from ..utils import deterministic_uuid
class AzureAISearch_VectorStore(VannaBase):
"""
AzureAISearch_VectorStore is a class that provides a vector store for Azure AI Search.
Args:
config (dict): Configuration dictionary. Defaults to {}. You must provide an API key in the config.
- azure_search_endpoint (str, optional): Azure Search endpoint. Defaults to "https://azcognetive.search.windows.net".
- azure_search_api_key (str): Azure Search API key.
- dimensions (int, optional): Dimensions of the embeddings. Defaults to 384 which corresponds to the dimensions of BAAI/bge-small-en-v1.5.
- fastembed_model (str, optional): Fastembed model to use. Defaults to "BAAI/bge-small-en-v1.5".
- index_name (str, optional): Name of the index. Defaults to "vanna-index".
- n_results (int, optional): Number of results to return. Defaults to 10.
- n_results_ddl (int, optional): Number of results to return for DDL queries. Defaults to the value of n_results.
- n_results_sql (int, optional): Number of results to return for SQL queries. Defaults to the value of n_results.
- n_results_documentation (int, optional): Number of results to return for documentation queries. Defaults to the value of n_results.
Raises:
ValueError: If config is None, or if 'azure_search_api_key' is not provided in the config.
"""
def __init__(self, config=None):
VannaBase.__init__(self, config=config)
self.config = config or None
if config is None:
raise ValueError(
"config is required, pass an API key, 'azure_search_api_key', in the config."
)
azure_search_endpoint = config.get("azure_search_endpoint", "https://azcognetive.search.windows.net")
azure_search_api_key = config.get("azure_search_api_key")
self.dimensions = config.get("dimensions", 384)
self.fastembed_model = config.get("fastembed_model", "BAAI/bge-small-en-v1.5")
self.index_name = config.get("index_name", "vanna-index")
self.n_results_ddl = config.get("n_results_ddl", config.get("n_results", 10))
self.n_results_sql = config.get("n_results_sql", config.get("n_results", 10))
self.n_results_documentation = config.get("n_results_documentation", config.get("n_results", 10))
if not azure_search_api_key:
raise ValueError(
"'azure_search_api_key' is required in config to use AzureAISearch_VectorStore"
)
self.index_client = SearchIndexClient(
endpoint=azure_search_endpoint,
credential=AzureKeyCredential(azure_search_api_key)
)
self.search_client = SearchClient(
endpoint=azure_search_endpoint,
index_name=self.index_name,
credential=AzureKeyCredential(azure_search_api_key)
)
if self.index_name not in self._get_indexes():
self._create_index()
def _create_index(self) -> bool:
fields = [
SearchableField(name="id", type=SearchFieldDataType.String, key=True, filterable=True),
SearchableField(name="document", type=SearchFieldDataType.String, searchable=True, filterable=True),
SearchField(name="type", type=SearchFieldDataType.String, filterable=True, searchable=True),
SearchField(name="document_vector", type=SearchFieldDataType.Collection(SearchFieldDataType.Single), searchable=True, vector_search_dimensions=self.dimensions, vector_search_profile_name="ExhaustiveKnnProfile"),
]
vector_search = VectorSearch(
algorithms=[
ExhaustiveKnnAlgorithmConfiguration(
name="ExhaustiveKnn",
kind=VectorSearchAlgorithmKind.EXHAUSTIVE_KNN,
parameters=ExhaustiveKnnParameters(
metric=VectorSearchAlgorithmMetric.COSINE
)
)
],
profiles=[
VectorSearchProfile(
name="ExhaustiveKnnProfile",
algorithm_configuration_name="ExhaustiveKnn",
)
]
)
index = SearchIndex(name=self.index_name, fields=fields, vector_search=vector_search)
result = self.index_client.create_or_update_index(index)
print(f'{result.name} created')
def _get_indexes(self) -> list:
return [index for index in self.index_client.list_index_names()]
def add_ddl(self, ddl: str) -> str:
id = deterministic_uuid(ddl) + "-ddl"
document = {
"id": id,
"document": ddl,
"type": "ddl",
"document_vector": self.generate_embedding(ddl)
}
self.search_client.upload_documents(documents=[document])
return id
def add_documentation(self, doc: str) -> str:
id = deterministic_uuid(doc) + "-doc"
document = {
"id": id,
"document": doc,
"type": "doc",
"document_vector": self.generate_embedding(doc)
}
self.search_client.upload_documents(documents=[document])
return id
def add_question_sql(self, question: str, sql: str) -> str:
question_sql_json = json.dumps({"question": question, "sql": sql}, ensure_ascii=False)
id = deterministic_uuid(question_sql_json) + "-sql"
document = {
"id": id,
"document": question_sql_json,
"type": "sql",
"document_vector": self.generate_embedding(question_sql_json)
}
self.search_client.upload_documents(documents=[document])
return id
def get_related_ddl(self, text: str) -> List[str]:
result = []
vector_query = VectorizedQuery(vector=self.generate_embedding(text), fields="document_vector")
df = pd.DataFrame(
self.search_client.search(
top=self.n_results_ddl,
vector_queries=[vector_query],
select=["id", "document", "type"],
filter=f"type eq 'ddl'"
)
)
if len(df):
result = df["document"].tolist()
return result
def get_related_documentation(self, text: str) -> List[str]:
result = []
vector_query = VectorizedQuery(vector=self.generate_embedding(text), fields="document_vector")
df = pd.DataFrame(
self.search_client.search(
top=self.n_results_documentation,
vector_queries=[vector_query],
select=["id", "document", "type"],
filter=f"type eq 'doc'",
vector_filter_mode=VectorFilterMode.PRE_FILTER
)
)
if len(df):
result = df["document"].tolist()
return result
def get_similar_question_sql(self, question: str) -> List[str]:
result = []
# Vectorize the text
vector_query = VectorizedQuery(vector=self.generate_embedding(question), fields="document_vector")
df = pd.DataFrame(
self.search_client.search(
top=self.n_results_sql,
vector_queries=[vector_query],
select=["id", "document", "type"],
filter=f"type eq 'sql'"
)
)
if len(df): # Check if there is similar query and the result is not empty
result = [ast.literal_eval(element) for element in df["document"].tolist()]
return result
def get_training_data(self) -> List[str]:
search = self.search_client.search(
search_text="*",
select=['id', 'document', 'type'],
filter=f"(type eq 'sql') or (type eq 'ddl') or (type eq 'doc')"
).by_page()
df = pd.DataFrame([item for page in search for item in page])
if len(df):
df.loc[df["type"] == "sql", "question"] = df.loc[df["type"] == "sql"]["document"].apply(lambda x: json.loads(x)["question"])
df.loc[df["type"] == "sql", "content"] = df.loc[df["type"] == "sql"]["document"].apply(lambda x: json.loads(x)["sql"])
df.loc[df["type"] != "sql", "content"] = df.loc[df["type"] != "sql"]["document"]
return df[["id", "question", "content", "type"]]
return pd.DataFrame()
def remove_training_data(self, id: str) -> bool:
result = self.search_client.delete_documents(documents=[{'id':id}])
return result[0].succeeded
def remove_index(self):
self.index_client.delete_index(self.index_name)
def generate_embedding(self, data: str, **kwargs) -> List[float]:
embedding_model = TextEmbedding(model_name=self.fastembed_model)
embedding = next(embedding_model.embed(data))
return embedding.tolist()
```
## /src/vanna/base/__init__.py
```py path="/src/vanna/base/__init__.py"
from .base import VannaBase
```
## /src/vanna/base/base.py
```py path="/src/vanna/base/base.py"
r"""
# Nomenclature
| Prefix | Definition | Examples |
| --- | --- | --- |
| `vn.get_` | Fetch some data | [`vn.get_related_ddl(...)`][vanna.base.base.VannaBase.get_related_ddl] |
| `vn.add_` | Adds something to the retrieval layer | [`vn.add_question_sql(...)`][vanna.base.base.VannaBase.add_question_sql]
[`vn.add_ddl(...)`][vanna.base.base.VannaBase.add_ddl] |
| `vn.generate_` | Generates something using AI based on the information in the model | [`vn.generate_sql(...)`][vanna.base.base.VannaBase.generate_sql]
[`vn.generate_explanation()`][vanna.base.base.VannaBase.generate_explanation] |
| `vn.run_` | Runs code (SQL) | [`vn.run_sql`][vanna.base.base.VannaBase.run_sql] |
| `vn.remove_` | Removes something from the retrieval layer | [`vn.remove_training_data`][vanna.base.base.VannaBase.remove_training_data] |
| `vn.connect_` | Connects to a database | [`vn.connect_to_snowflake(...)`][vanna.base.base.VannaBase.connect_to_snowflake] |
| `vn.update_` | Updates something | N/A -- unused |
| `vn.set_` | Sets something | N/A -- unused |
# Open-Source and Extending
Vanna.AI is open-source and extensible. If you'd like to use Vanna without the servers, see an example [here](https://vanna.ai/docs/postgres-ollama-chromadb/).
The following is an example of where various functions are implemented in the codebase when using the default "local" version of Vanna. `vanna.base.VannaBase` is the base class which provides a `vanna.base.VannaBase.ask` and `vanna.base.VannaBase.train` function. Those rely on abstract methods which are implemented in the subclasses `vanna.openai_chat.OpenAI_Chat` and `vanna.chromadb_vector.ChromaDB_VectorStore`. `vanna.openai_chat.OpenAI_Chat` uses the OpenAI API to generate SQL and Plotly code. `vanna.chromadb_vector.ChromaDB_VectorStore` uses ChromaDB to store training data and generate embeddings.
If you want to use Vanna with other LLMs or databases, you can create your own subclass of `vanna.base.VannaBase` and implement the abstract methods.
\`\`\`mermaid
flowchart
subgraph VannaBase
ask
train
end
subgraph OpenAI_Chat
get_sql_prompt
submit_prompt
generate_question
generate_plotly_code
end
subgraph ChromaDB_VectorStore
generate_embedding
add_question_sql
add_ddl
add_documentation
get_similar_question_sql
get_related_ddl
get_related_documentation
end
\`\`\`
"""
import json
import os
import re
import sqlite3
import traceback
from abc import ABC, abstractmethod
from typing import List, Tuple, Union
from urllib.parse import urlparse
import pandas as pd
import plotly
import plotly.express as px
import plotly.graph_objects as go
import requests
import sqlparse
from ..exceptions import DependencyError, ImproperlyConfigured, ValidationError
from ..types import TrainingPlan, TrainingPlanItem
from ..utils import validate_config_path
class VannaBase(ABC):
def __init__(self, config=None):
if config is None:
config = {}
self.config = config
self.run_sql_is_set = False
self.static_documentation = ""
self.dialect = self.config.get("dialect", "SQL")
self.language = self.config.get("language", None)
self.max_tokens = self.config.get("max_tokens", 14000)
def log(self, message: str, title: str = "Info"):
print(f"{title}: {message}")
def _response_language(self) -> str:
if self.language is None:
return ""
return f"Respond in the {self.language} language."
def generate_sql(self, question: str, allow_llm_to_see_data=False, **kwargs) -> str:
"""
Example:
\`\`\`python
vn.generate_sql("What are the top 10 customers by sales?")
\`\`\`
Uses the LLM to generate a SQL query that answers a question. It runs the following methods:
- [`get_similar_question_sql`][vanna.base.base.VannaBase.get_similar_question_sql]
- [`get_related_ddl`][vanna.base.base.VannaBase.get_related_ddl]
- [`get_related_documentation`][vanna.base.base.VannaBase.get_related_documentation]
- [`get_sql_prompt`][vanna.base.base.VannaBase.get_sql_prompt]
- [`submit_prompt`][vanna.base.base.VannaBase.submit_prompt]
Args:
question (str): The question to generate a SQL query for.
allow_llm_to_see_data (bool): Whether to allow the LLM to see the data (for the purposes of introspecting the data to generate the final SQL).
Returns:
str: The SQL query that answers the question.
"""
if self.config is not None:
initial_prompt = self.config.get("initial_prompt", None)
else:
initial_prompt = None
question_sql_list = self.get_similar_question_sql(question, **kwargs)
ddl_list = self.get_related_ddl(question, **kwargs)
doc_list = self.get_related_documentation(question, **kwargs)
prompt = self.get_sql_prompt(
initial_prompt=initial_prompt,
question=question,
question_sql_list=question_sql_list,
ddl_list=ddl_list,
doc_list=doc_list,
**kwargs,
)
self.log(title="SQL Prompt", message=prompt)
llm_response = self.submit_prompt(prompt, **kwargs)
self.log(title="LLM Response", message=llm_response)
if 'intermediate_sql' in llm_response:
if not allow_llm_to_see_data:
return "The LLM is not allowed to see the data in your database. Your question requires database introspection to generate the necessary SQL. Please set allow_llm_to_see_data=True to enable this."
if allow_llm_to_see_data:
intermediate_sql = self.extract_sql(llm_response)
try:
self.log(title="Running Intermediate SQL", message=intermediate_sql)
df = self.run_sql(intermediate_sql)
prompt = self.get_sql_prompt(
initial_prompt=initial_prompt,
question=question,
question_sql_list=question_sql_list,
ddl_list=ddl_list,
doc_list=doc_list+[f"The following is a pandas DataFrame with the results of the intermediate SQL query {intermediate_sql}: \n" + df.to_markdown()],
**kwargs,
)
self.log(title="Final SQL Prompt", message=prompt)
llm_response = self.submit_prompt(prompt, **kwargs)
self.log(title="LLM Response", message=llm_response)
except Exception as e:
return f"Error running intermediate SQL: {e}"
return self.extract_sql(llm_response)
def extract_sql(self, llm_response: str) -> str:
"""
Example:
\`\`\`python
vn.extract_sql("Here's the SQL query in a code block: \`\`\`sql\nSELECT * FROM customers\n\`\`\`")
\`\`\`
Extracts the SQL query from the LLM response. This is useful in case the LLM response contains other information besides the SQL query.
Override this function if your LLM responses need custom extraction logic.
Args:
llm_response (str): The LLM response.
Returns:
str: The extracted SQL query.
"""
import re
"""
Extracts the SQL query from the LLM response, handling various formats including:
- WITH clause
- SELECT statement
- CREATE TABLE AS SELECT
- Markdown code blocks
"""
# Match CREATE TABLE ... AS SELECT
sqls = re.findall(r"\bCREATE\s+TABLE\b.*?\bAS\b.*?;", llm_response, re.DOTALL | re.IGNORECASE)
if sqls:
sql = sqls[-1]
self.log(title="Extracted SQL", message=f"{sql}")
return sql
# Match WITH clause (CTEs)
sqls = re.findall(r"\bWITH\b .*?;", llm_response, re.DOTALL | re.IGNORECASE)
if sqls:
sql = sqls[-1]
self.log(title="Extracted SQL", message=f"{sql}")
return sql
# Match SELECT ... ;
sqls = re.findall(r"\bSELECT\b .*?;", llm_response, re.DOTALL | re.IGNORECASE)
if sqls:
sql = sqls[-1]
self.log(title="Extracted SQL", message=f"{sql}")
return sql
# Match \`\`\`sql ... \`\`\` blocks
sqls = re.findall(r"\`\`\`sql\s*\n(.*?)\`\`\`", llm_response, re.DOTALL | re.IGNORECASE)
if sqls:
sql = sqls[-1].strip()
self.log(title="Extracted SQL", message=f"{sql}")
return sql
# Match any \`\`\` ... \`\`\` code blocks
sqls = re.findall(r"\`\`\`(.*?)\`\`\`", llm_response, re.DOTALL | re.IGNORECASE)
if sqls:
sql = sqls[-1].strip()
self.log(title="Extracted SQL", message=f"{sql}")
return sql
return llm_response
def is_sql_valid(self, sql: str) -> bool:
"""
Example:
\`\`\`python
vn.is_sql_valid("SELECT * FROM customers")
\`\`\`
Checks if the SQL query is valid. This is usually used to check if we should run the SQL query or not.
By default it checks if the SQL query is a SELECT statement. You can override this method to enable running other types of SQL queries.
Args:
sql (str): The SQL query to check.
Returns:
bool: True if the SQL query is valid, False otherwise.
"""
parsed = sqlparse.parse(sql)
for statement in parsed:
if statement.get_type() == 'SELECT':
return True
return False
def should_generate_chart(self, df: pd.DataFrame) -> bool:
"""
Example:
\`\`\`python
vn.should_generate_chart(df)
\`\`\`
Checks if a chart should be generated for the given DataFrame. By default, it checks if the DataFrame has more than one row and has numerical columns.
You can override this method to customize the logic for generating charts.
Args:
df (pd.DataFrame): The DataFrame to check.
Returns:
bool: True if a chart should be generated, False otherwise.
"""
if len(df) > 1 and df.select_dtypes(include=['number']).shape[1] > 0:
return True
return False
def generate_rewritten_question(self, last_question: str, new_question: str, **kwargs) -> str:
"""
**Example:**
\`\`\`python
rewritten_question = vn.generate_rewritten_question("Who are the top 5 customers by sales?", "Show me their email addresses")
\`\`\`
Generate a rewritten question by combining the last question and the new question if they are related. If the new question is self-contained and not related to the last question, return the new question.
Args:
last_question (str): The previous question that was asked.
new_question (str): The new question to be combined with the last question.
**kwargs: Additional keyword arguments.
Returns:
str: The combined question if related, otherwise the new question.
"""
if last_question is None:
return new_question
prompt = [
self.system_message("Your goal is to combine a sequence of questions into a singular question if they are related. If the second question does not relate to the first question and is fully self-contained, return the second question. Return just the new combined question with no additional explanations. The question should theoretically be answerable with a single SQL statement."),
self.user_message("First question: " + last_question + "\nSecond question: " + new_question),
]
return self.submit_prompt(prompt=prompt, **kwargs)
def generate_followup_questions(
self, question: str, sql: str, df: pd.DataFrame, n_questions: int = 5, **kwargs
) -> list:
"""
**Example:**
\`\`\`python
vn.generate_followup_questions("What are the top 10 customers by sales?", sql, df)
\`\`\`
Generate a list of followup questions that you can ask Vanna.AI.
Args:
question (str): The question that was asked.
sql (str): The LLM-generated SQL query.
df (pd.DataFrame): The results of the SQL query.
n_questions (int): Number of follow-up questions to generate.
Returns:
list: A list of followup questions that you can ask Vanna.AI.
"""
message_log = [
self.system_message(
f"You are a helpful data assistant. The user asked the question: '{question}'\n\nThe SQL query for this question was: {sql}\n\nThe following is a pandas DataFrame with the results of the query: \n{df.head(25).to_markdown()}\n\n"
),
self.user_message(
f"Generate a list of {n_questions} followup questions that the user might ask about this data. Respond with a list of questions, one per line. Do not answer with any explanations -- just the questions. Remember that there should be an unambiguous SQL query that can be generated from the question. Prefer questions that are answerable outside of the context of this conversation. Prefer questions that are slight modifications of the SQL query that was generated that allow digging deeper into the data. Each question will be turned into a button that the user can click to generate a new SQL query so don't use 'example' type questions. Each question must have a one-to-one correspondence with an instantiated SQL query." +
self._response_language()
),
]
llm_response = self.submit_prompt(message_log, **kwargs)
numbers_removed = re.sub(r"^\d+\.\s*", "", llm_response, flags=re.MULTILINE)
return numbers_removed.split("\n")
def generate_questions(self, **kwargs) -> List[str]:
"""
**Example:**
\`\`\`python
vn.generate_questions()
\`\`\`
Generate a list of questions that you can ask Vanna.AI.
"""
question_sql = self.get_similar_question_sql(question="", **kwargs)
return [q["question"] for q in question_sql]
def generate_summary(self, question: str, df: pd.DataFrame, **kwargs) -> str:
"""
**Example:**
\`\`\`python
vn.generate_summary("What are the top 10 customers by sales?", df)
\`\`\`
Generate a summary of the results of a SQL query.
Args:
question (str): The question that was asked.
df (pd.DataFrame): The results of the SQL query.
Returns:
str: The summary of the results of the SQL query.
"""
message_log = [
self.system_message(
f"You are a helpful data assistant. The user asked the question: '{question}'\n\nThe following is a pandas DataFrame with the results of the query: \n{df.to_markdown()}\n\n"
),
self.user_message(
"Briefly summarize the data based on the question that was asked. Do not respond with any additional explanation beyond the summary." +
self._response_language()
),
]
summary = self.submit_prompt(message_log, **kwargs)
return summary
# ----------------- Use Any Embeddings API ----------------- #
@abstractmethod
def generate_embedding(self, data: str, **kwargs) -> List[float]:
pass
# ----------------- Use Any Database to Store and Retrieve Context ----------------- #
@abstractmethod
def get_similar_question_sql(self, question: str, **kwargs) -> list:
"""
This method is used to get similar questions and their corresponding SQL statements.
Args:
question (str): The question to get similar questions and their corresponding SQL statements for.
Returns:
list: A list of similar questions and their corresponding SQL statements.
"""
pass
@abstractmethod
def get_related_ddl(self, question: str, **kwargs) -> list:
"""
This method is used to get related DDL statements to a question.
Args:
question (str): The question to get related DDL statements for.
Returns:
list: A list of related DDL statements.
"""
pass
@abstractmethod
def get_related_documentation(self, question: str, **kwargs) -> list:
"""
This method is used to get related documentation to a question.
Args:
question (str): The question to get related documentation for.
Returns:
list: A list of related documentation.
"""
pass
@abstractmethod
def add_question_sql(self, question: str, sql: str, **kwargs) -> str:
"""
This method is used to add a question and its corresponding SQL query to the training data.
Args:
question (str): The question to add.
sql (str): The SQL query to add.
Returns:
str: The ID of the training data that was added.
"""
pass
@abstractmethod
def add_ddl(self, ddl: str, **kwargs) -> str:
"""
This method is used to add a DDL statement to the training data.
Args:
ddl (str): The DDL statement to add.
Returns:
str: The ID of the training data that was added.
"""
pass
@abstractmethod
def add_documentation(self, documentation: str, **kwargs) -> str:
"""
This method is used to add documentation to the training data.
Args:
documentation (str): The documentation to add.
Returns:
str: The ID of the training data that was added.
"""
pass
@abstractmethod
def get_training_data(self, **kwargs) -> pd.DataFrame:
"""
Example:
\`\`\`python
vn.get_training_data()
\`\`\`
This method is used to get all the training data from the retrieval layer.
Returns:
pd.DataFrame: The training data.
"""
pass
@abstractmethod
def remove_training_data(self, id: str, **kwargs) -> bool:
"""
Example:
\`\`\`python
vn.remove_training_data(id="123-ddl")
\`\`\`
This method is used to remove training data from the retrieval layer.
Args:
id (str): The ID of the training data to remove.
Returns:
bool: True if the training data was removed, False otherwise.
"""
pass
# ----------------- Use Any Language Model API ----------------- #
@abstractmethod
def system_message(self, message: str) -> any:
pass
@abstractmethod
def user_message(self, message: str) -> any:
pass
@abstractmethod
def assistant_message(self, message: str) -> any:
pass
def str_to_approx_token_count(self, string: str) -> int:
return len(string) / 4
def add_ddl_to_prompt(
self, initial_prompt: str, ddl_list: list[str], max_tokens: int = 14000
) -> str:
if len(ddl_list) > 0:
initial_prompt += "\n===Tables \n"
for ddl in ddl_list:
if (
self.str_to_approx_token_count(initial_prompt)
+ self.str_to_approx_token_count(ddl)
< max_tokens
):
initial_prompt += f"{ddl}\n\n"
return initial_prompt
def add_documentation_to_prompt(
self,
initial_prompt: str,
documentation_list: list[str],
max_tokens: int = 14000,
) -> str:
if len(documentation_list) > 0:
initial_prompt += "\n===Additional Context \n\n"
for documentation in documentation_list:
if (
self.str_to_approx_token_count(initial_prompt)
+ self.str_to_approx_token_count(documentation)
< max_tokens
):
initial_prompt += f"{documentation}\n\n"
return initial_prompt
def add_sql_to_prompt(
self, initial_prompt: str, sql_list: list[str], max_tokens: int = 14000
) -> str:
if len(sql_list) > 0:
initial_prompt += "\n===Question-SQL Pairs\n\n"
for question in sql_list:
if (
self.str_to_approx_token_count(initial_prompt)
+ self.str_to_approx_token_count(question["sql"])
< max_tokens
):
initial_prompt += f"{question['question']}\n{question['sql']}\n\n"
return initial_prompt
def get_sql_prompt(
self,
initial_prompt : str,
question: str,
question_sql_list: list,
ddl_list: list,
doc_list: list,
**kwargs,
):
"""
Example:
\`\`\`python
vn.get_sql_prompt(
question="What are the top 10 customers by sales?",
question_sql_list=[{"question": "What are the top 10 customers by sales?", "sql": "SELECT * FROM customers ORDER BY sales DESC LIMIT 10"}],
ddl_list=["CREATE TABLE customers (id INT, name TEXT, sales DECIMAL)"],
doc_list=["The customers table contains information about customers and their sales."],
)
\`\`\`
This method is used to generate a prompt for the LLM to generate SQL.
Args:
question (str): The question to generate SQL for.
question_sql_list (list): A list of questions and their corresponding SQL statements.
ddl_list (list): A list of DDL statements.
doc_list (list): A list of documentation.
Returns:
any: The prompt for the LLM to generate SQL.
"""
if initial_prompt is None:
initial_prompt = f"You are a {self.dialect} expert. " + \
"Please help to generate a SQL query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions. "
initial_prompt = self.add_ddl_to_prompt(
initial_prompt, ddl_list, max_tokens=self.max_tokens
)
if self.static_documentation != "":
doc_list.append(self.static_documentation)
initial_prompt = self.add_documentation_to_prompt(
initial_prompt, doc_list, max_tokens=self.max_tokens
)
initial_prompt += (
"===Response Guidelines \n"
"1. If the provided context is sufficient, please generate a valid SQL query without any explanations for the question. \n"
"2. If the provided context is almost sufficient but requires knowledge of a specific string in a particular column, please generate an intermediate SQL query to find the distinct strings in that column. Prepend the query with a comment saying intermediate_sql \n"
"3. If the provided context is insufficient, please explain why it can't be generated. \n"
"4. Please use the most relevant table(s). \n"
"5. If the question has been asked and answered before, please repeat the answer exactly as it was given before. \n"
f"6. Ensure that the output SQL is {self.dialect}-compliant and executable, and free of syntax errors. \n"
)
message_log = [self.system_message(initial_prompt)]
for example in question_sql_list:
if example is None:
print("example is None")
else:
if example is not None and "question" in example and "sql" in example:
message_log.append(self.user_message(example["question"]))
message_log.append(self.assistant_message(example["sql"]))
message_log.append(self.user_message(question))
return message_log
def get_followup_questions_prompt(
self,
question: str,
question_sql_list: list,
ddl_list: list,
doc_list: list,
**kwargs,
) -> list:
initial_prompt = f"The user initially asked the question: '{question}': \n\n"
initial_prompt = self.add_ddl_to_prompt(
initial_prompt, ddl_list, max_tokens=self.max_tokens
)
initial_prompt = self.add_documentation_to_prompt(
initial_prompt, doc_list, max_tokens=self.max_tokens
)
initial_prompt = self.add_sql_to_prompt(
initial_prompt, question_sql_list, max_tokens=self.max_tokens
)
message_log = [self.system_message(initial_prompt)]
message_log.append(
self.user_message(
"Generate a list of followup questions that the user might ask about this data. Respond with a list of questions, one per line. Do not answer with any explanations -- just the questions."
)
)
return message_log
@abstractmethod
def submit_prompt(self, prompt, **kwargs) -> str:
"""
Example:
\`\`\`python
vn.submit_prompt(
[
vn.system_message("The user will give you SQL and you will try to guess what the business question this query is answering. Return just the question without any additional explanation. Do not reference the table name in the question."),
vn.user_message("What are the top 10 customers by sales?"),
]
)
\`\`\`
This method is used to submit a prompt to the LLM.
Args:
prompt (any): The prompt to submit to the LLM.
Returns:
str: The response from the LLM.
"""
pass
def generate_question(self, sql: str, **kwargs) -> str:
response = self.submit_prompt(
[
self.system_message(
"The user will give you SQL and you will try to guess what the business question this query is answering. Return just the question without any additional explanation. Do not reference the table name in the question."
),
self.user_message(sql),
],
**kwargs,
)
return response
def _extract_python_code(self, markdown_string: str) -> str:
# Strip whitespace to avoid indentation errors in LLM-generated code
markdown_string = markdown_string.strip()
# Regex pattern to match Python code blocks
pattern = r"\`\`\`[\w\s]*python\n([\s\S]*?)\`\`\`|\`\`\`([\s\S]*?)\`\`\`"
# Find all matches in the markdown string
matches = re.findall(pattern, markdown_string, re.IGNORECASE)
# Extract the Python code from the matches
python_code = []
for match in matches:
python = match[0] if match[0] else match[1]
python_code.append(python.strip())
if len(python_code) == 0:
return markdown_string
return python_code[0]
def _sanitize_plotly_code(self, raw_plotly_code: str) -> str:
# Remove the fig.show() statement from the plotly code
plotly_code = raw_plotly_code.replace("fig.show()", "")
return plotly_code
def generate_plotly_code(
self, question: str = None, sql: str = None, df_metadata: str = None, **kwargs
) -> str:
if question is not None:
system_msg = f"The following is a pandas DataFrame that contains the results of the query that answers the question the user asked: '{question}'"
else:
system_msg = "The following is a pandas DataFrame "
if sql is not None:
system_msg += f"\n\nThe DataFrame was produced using this query: {sql}\n\n"
system_msg += f"The following is information about the resulting pandas DataFrame 'df': \n{df_metadata}"
message_log = [
self.system_message(system_msg),
self.user_message(
"Can you generate the Python plotly code to chart the results of the dataframe? Assume the data is in a pandas dataframe called 'df'. If there is only one value in the dataframe, use an Indicator. Respond with only Python code. Do not answer with any explanations -- just the code."
),
]
plotly_code = self.submit_prompt(message_log, kwargs=kwargs)
return self._sanitize_plotly_code(self._extract_python_code(plotly_code))
# ----------------- Connect to Any Database to run the Generated SQL ----------------- #
def connect_to_snowflake(
self,
account: str,
username: str,
password: str,
database: str,
role: Union[str, None] = None,
warehouse: Union[str, None] = None,
**kwargs
):
try:
snowflake = __import__("snowflake.connector")
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method, run command:"
" \npip install vanna[snowflake]"
)
if username == "my-username":
username_env = os.getenv("SNOWFLAKE_USERNAME")
if username_env is not None:
username = username_env
else:
raise ImproperlyConfigured("Please set your Snowflake username.")
if password == "mypassword":
password_env = os.getenv("SNOWFLAKE_PASSWORD")
if password_env is not None:
password = password_env
else:
raise ImproperlyConfigured("Please set your Snowflake password.")
if account == "my-account":
account_env = os.getenv("SNOWFLAKE_ACCOUNT")
if account_env is not None:
account = account_env
else:
raise ImproperlyConfigured("Please set your Snowflake account.")
if database == "my-database":
database_env = os.getenv("SNOWFLAKE_DATABASE")
if database_env is not None:
database = database_env
else:
raise ImproperlyConfigured("Please set your Snowflake database.")
conn = snowflake.connector.connect(
user=username,
password=password,
account=account,
database=database,
client_session_keep_alive=True,
**kwargs
)
def run_sql_snowflake(sql: str) -> pd.DataFrame:
cs = conn.cursor()
if role is not None:
cs.execute(f"USE ROLE {role}")
if warehouse is not None:
cs.execute(f"USE WAREHOUSE {warehouse}")
cs.execute(f"USE DATABASE {database}")
cur = cs.execute(sql)
results = cur.fetchall()
# Create a pandas dataframe from the results
df = pd.DataFrame(results, columns=[desc[0] for desc in cur.description])
return df
self.dialect = "Snowflake SQL"
self.run_sql = run_sql_snowflake
self.run_sql_is_set = True
def connect_to_sqlite(self, url: str, check_same_thread: bool = False, **kwargs):
"""
Connect to a SQLite database. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
Args:
url (str): The URL of the database to connect to.
check_same_thread (str): Allow the connection may be accessed in multiple threads.
Returns:
None
"""
# URL of the database to download
# Path to save the downloaded database
path = os.path.basename(urlparse(url).path)
# Download the database if it doesn't exist
if not os.path.exists(url):
response = requests.get(url)
response.raise_for_status() # Check that the request was successful
with open(path, "wb") as f:
f.write(response.content)
url = path
# Connect to the database
conn = sqlite3.connect(
url,
check_same_thread=check_same_thread,
**kwargs
)
def run_sql_sqlite(sql: str):
return pd.read_sql_query(sql, conn)
self.dialect = "SQLite"
self.run_sql = run_sql_sqlite
self.run_sql_is_set = True
def connect_to_postgres(
self,
host: str = None,
dbname: str = None,
user: str = None,
password: str = None,
port: int = None,
**kwargs
):
"""
Connect to postgres using the psycopg2 connector. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
**Example:**
\`\`\`python
vn.connect_to_postgres(
host="myhost",
dbname="mydatabase",
user="myuser",
password="mypassword",
port=5432
)
\`\`\`
Args:
host (str): The postgres host.
dbname (str): The postgres database name.
user (str): The postgres user.
password (str): The postgres password.
port (int): The postgres Port.
"""
try:
import psycopg2
import psycopg2.extras
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: \npip install vanna[postgres]"
)
if not host:
host = os.getenv("HOST")
if not host:
raise ImproperlyConfigured("Please set your postgres host")
if not dbname:
dbname = os.getenv("DATABASE")
if not dbname:
raise ImproperlyConfigured("Please set your postgres database")
if not user:
user = os.getenv("PG_USER")
if not user:
raise ImproperlyConfigured("Please set your postgres user")
if not password:
password = os.getenv("PASSWORD")
if not password:
raise ImproperlyConfigured("Please set your postgres password")
if not port:
port = os.getenv("PORT")
if not port:
raise ImproperlyConfigured("Please set your postgres port")
conn = None
try:
conn = psycopg2.connect(
host=host,
dbname=dbname,
user=user,
password=password,
port=port,
**kwargs
)
except psycopg2.Error as e:
raise ValidationError(e)
def connect_to_db():
return psycopg2.connect(host=host, dbname=dbname,
user=user, password=password, port=port, **kwargs)
def run_sql_postgres(sql: str) -> Union[pd.DataFrame, None]:
conn = None
try:
conn = connect_to_db() # Initial connection attempt
cs = conn.cursor()
cs.execute(sql)
results = cs.fetchall()
# Create a pandas dataframe from the results
df = pd.DataFrame(results, columns=[desc[0] for desc in cs.description])
return df
except psycopg2.InterfaceError as e:
# Attempt to reconnect and retry the operation
if conn:
conn.close() # Ensure any existing connection is closed
conn = connect_to_db()
cs = conn.cursor()
cs.execute(sql)
results = cs.fetchall()
# Create a pandas dataframe from the results
df = pd.DataFrame(results, columns=[desc[0] for desc in cs.description])
return df
except psycopg2.Error as e:
if conn:
conn.rollback()
raise ValidationError(e)
except Exception as e:
conn.rollback()
raise e
self.dialect = "PostgreSQL"
self.run_sql_is_set = True
self.run_sql = run_sql_postgres
def connect_to_mysql(
self,
host: str = None,
dbname: str = None,
user: str = None,
password: str = None,
port: int = None,
**kwargs
):
try:
import pymysql.cursors
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: \npip install PyMySQL"
)
if not host:
host = os.getenv("HOST")
if not host:
raise ImproperlyConfigured("Please set your MySQL host")
if not dbname:
dbname = os.getenv("DATABASE")
if not dbname:
raise ImproperlyConfigured("Please set your MySQL database")
if not user:
user = os.getenv("USER")
if not user:
raise ImproperlyConfigured("Please set your MySQL user")
if not password:
password = os.getenv("PASSWORD")
if not password:
raise ImproperlyConfigured("Please set your MySQL password")
if not port:
port = os.getenv("PORT")
if not port:
raise ImproperlyConfigured("Please set your MySQL port")
conn = None
try:
conn = pymysql.connect(
host=host,
user=user,
password=password,
database=dbname,
port=port,
cursorclass=pymysql.cursors.DictCursor,
**kwargs
)
except pymysql.Error as e:
raise ValidationError(e)
def run_sql_mysql(sql: str) -> Union[pd.DataFrame, None]:
if conn:
try:
conn.ping(reconnect=True)
cs = conn.cursor()
cs.execute(sql)
results = cs.fetchall()
# Create a pandas dataframe from the results
df = pd.DataFrame(
results, columns=[desc[0] for desc in cs.description]
)
return df
except pymysql.Error as e:
conn.rollback()
raise ValidationError(e)
except Exception as e:
conn.rollback()
raise e
self.run_sql_is_set = True
self.run_sql = run_sql_mysql
def connect_to_clickhouse(
self,
host: str = None,
dbname: str = None,
user: str = None,
password: str = None,
port: int = None,
**kwargs
):
try:
import clickhouse_connect
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: \npip install clickhouse_connect"
)
if not host:
host = os.getenv("HOST")
if not host:
raise ImproperlyConfigured("Please set your ClickHouse host")
if not dbname:
dbname = os.getenv("DATABASE")
if not dbname:
raise ImproperlyConfigured("Please set your ClickHouse database")
if not user:
user = os.getenv("USER")
if not user:
raise ImproperlyConfigured("Please set your ClickHouse user")
if not password:
password = os.getenv("PASSWORD")
if not password:
raise ImproperlyConfigured("Please set your ClickHouse password")
if not port:
port = os.getenv("PORT")
if not port:
raise ImproperlyConfigured("Please set your ClickHouse port")
conn = None
try:
conn = clickhouse_connect.get_client(
host=host,
port=port,
username=user,
password=password,
database=dbname,
**kwargs
)
print(conn)
except Exception as e:
raise ValidationError(e)
def run_sql_clickhouse(sql: str) -> Union[pd.DataFrame, None]:
if conn:
try:
result = conn.query(sql)
results = result.result_rows
# Create a pandas dataframe from the results
df = pd.DataFrame(results, columns=result.column_names)
return df
except Exception as e:
raise e
self.run_sql_is_set = True
self.run_sql = run_sql_clickhouse
def connect_to_oracle(
self,
user: str = None,
password: str = None,
dsn: str = None,
**kwargs
):
"""
Connect to an Oracle db using oracledb package. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
**Example:**
\`\`\`python
vn.connect_to_oracle(
user="username",
password="password",
dsn="host:port/sid",
)
\`\`\`
Args:
USER (str): Oracle db user name.
PASSWORD (str): Oracle db user password.
DSN (str): Oracle db host ip - host:port/sid.
"""
try:
import oracledb
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: \npip install oracledb"
)
if not dsn:
dsn = os.getenv("DSN")
if not dsn:
raise ImproperlyConfigured("Please set your Oracle dsn which should include host:port/sid")
if not user:
user = os.getenv("USER")
if not user:
raise ImproperlyConfigured("Please set your Oracle db user")
if not password:
password = os.getenv("PASSWORD")
if not password:
raise ImproperlyConfigured("Please set your Oracle db password")
conn = None
try:
conn = oracledb.connect(
user=user,
password=password,
dsn=dsn,
**kwargs
)
except oracledb.Error as e:
raise ValidationError(e)
def run_sql_oracle(sql: str) -> Union[pd.DataFrame, None]:
if conn:
try:
sql = sql.rstrip()
if sql.endswith(';'): #fix for a known problem with Oracle db where an extra ; will cause an error.
sql = sql[:-1]
cs = conn.cursor()
cs.execute(sql)
results = cs.fetchall()
# Create a pandas dataframe from the results
df = pd.DataFrame(
results, columns=[desc[0] for desc in cs.description]
)
return df
except oracledb.Error as e:
conn.rollback()
raise ValidationError(e)
except Exception as e:
conn.rollback()
raise e
self.run_sql_is_set = True
self.run_sql = run_sql_oracle
def connect_to_bigquery(
self,
cred_file_path: str = None,
project_id: str = None,
**kwargs
):
"""
Connect to gcs using the bigquery connector. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
**Example:**
\`\`\`python
vn.connect_to_bigquery(
project_id="myprojectid",
cred_file_path="path/to/credentials.json",
)
\`\`\`
Args:
project_id (str): The gcs project id.
cred_file_path (str): The gcs credential file path
"""
try:
from google.api_core.exceptions import GoogleAPIError
from google.cloud import bigquery
from google.oauth2 import service_account
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method, run command:"
" \npip install vanna[bigquery]"
)
if not project_id:
project_id = os.getenv("PROJECT_ID")
if not project_id:
raise ImproperlyConfigured("Please set your Google Cloud Project ID.")
import sys
if "google.colab" in sys.modules:
try:
from google.colab import auth
auth.authenticate_user()
except Exception as e:
raise ImproperlyConfigured(e)
else:
print("Not using Google Colab.")
conn = None
if not cred_file_path:
try:
conn = bigquery.Client(project=project_id)
except:
print("Could not found any google cloud implicit credentials")
else:
# Validate file path and pemissions
validate_config_path(cred_file_path)
if not conn:
with open(cred_file_path, "r") as f:
credentials = service_account.Credentials.from_service_account_info(
json.loads(f.read()),
scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
try:
conn = bigquery.Client(
project=project_id,
credentials=credentials,
**kwargs
)
except:
raise ImproperlyConfigured(
"Could not connect to bigquery please correct credentials"
)
def run_sql_bigquery(sql: str) -> Union[pd.DataFrame, None]:
if conn:
job = conn.query(sql)
df = job.result().to_dataframe()
return df
return None
self.dialect = "BigQuery SQL"
self.run_sql_is_set = True
self.run_sql = run_sql_bigquery
def connect_to_duckdb(self, url: str, init_sql: str = None, **kwargs):
"""
Connect to a DuckDB database. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
Args:
url (str): The URL of the database to connect to. Use :memory: to create an in-memory database. Use md: or motherduck: to use the MotherDuck database.
init_sql (str, optional): SQL to run when connecting to the database. Defaults to None.
Returns:
None
"""
try:
import duckdb
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: \npip install vanna[duckdb]"
)
# URL of the database to download
if url == ":memory:" or url == "":
path = ":memory:"
else:
# Path to save the downloaded database
print(os.path.exists(url))
if os.path.exists(url):
path = url
elif url.startswith("md") or url.startswith("motherduck"):
path = url
else:
path = os.path.basename(urlparse(url).path)
# Download the database if it doesn't exist
if not os.path.exists(path):
response = requests.get(url)
response.raise_for_status() # Check that the request was successful
with open(path, "wb") as f:
f.write(response.content)
# Connect to the database
conn = duckdb.connect(path, **kwargs)
if init_sql:
conn.query(init_sql)
def run_sql_duckdb(sql: str):
return conn.query(sql).to_df()
self.dialect = "DuckDB SQL"
self.run_sql = run_sql_duckdb
self.run_sql_is_set = True
def connect_to_mssql(self, odbc_conn_str: str, **kwargs):
"""
Connect to a Microsoft SQL Server database. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
Args:
odbc_conn_str (str): The ODBC connection string.
Returns:
None
"""
try:
import pyodbc
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: pip install pyodbc"
)
try:
import sqlalchemy as sa
from sqlalchemy.engine import URL
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: pip install sqlalchemy"
)
connection_url = URL.create(
"mssql+pyodbc", query={"odbc_connect": odbc_conn_str}
)
from sqlalchemy import create_engine
engine = create_engine(connection_url, **kwargs)
def run_sql_mssql(sql: str):
# Execute the SQL statement and return the result as a pandas DataFrame
with engine.begin() as conn:
df = pd.read_sql_query(sa.text(sql), conn)
conn.close()
return df
raise Exception("Couldn't run sql")
self.dialect = "T-SQL / Microsoft SQL Server"
self.run_sql = run_sql_mssql
self.run_sql_is_set = True
def connect_to_presto(
self,
host: str,
catalog: str = 'hive',
schema: str = 'default',
user: str = None,
password: str = None,
port: int = None,
combined_pem_path: str = None,
protocol: str = 'https',
requests_kwargs: dict = None,
**kwargs
):
"""
Connect to a Presto database using the specified parameters.
Args:
host (str): The host address of the Presto database.
catalog (str): The catalog to use in the Presto environment.
schema (str): The schema to use in the Presto environment.
user (str): The username for authentication.
password (str): The password for authentication.
port (int): The port number for the Presto connection.
combined_pem_path (str): The path to the combined pem file for SSL connection.
protocol (str): The protocol to use for the connection (default is 'https').
requests_kwargs (dict): Additional keyword arguments for requests.
Raises:
DependencyError: If required dependencies are not installed.
ImproperlyConfigured: If essential configuration settings are missing.
Returns:
None
"""
try:
from pyhive import presto
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: \npip install pyhive"
)
if not host:
host = os.getenv("PRESTO_HOST")
if not host:
raise ImproperlyConfigured("Please set your presto host")
if not catalog:
catalog = os.getenv("PRESTO_CATALOG")
if not catalog:
raise ImproperlyConfigured("Please set your presto catalog")
if not user:
user = os.getenv("PRESTO_USER")
if not user:
raise ImproperlyConfigured("Please set your presto user")
if not password:
password = os.getenv("PRESTO_PASSWORD")
if not port:
port = os.getenv("PRESTO_PORT")
if not port:
raise ImproperlyConfigured("Please set your presto port")
conn = None
try:
if requests_kwargs is None and combined_pem_path is not None:
# use the combined pem file to verify the SSL connection
requests_kwargs = {
'verify': combined_pem_path, # 使用转换后得到的 PEM 文件进行 SSL 验证
}
conn = presto.Connection(host=host,
username=user,
password=password,
catalog=catalog,
schema=schema,
port=port,
protocol=protocol,
requests_kwargs=requests_kwargs,
**kwargs)
except presto.Error as e:
raise ValidationError(e)
def run_sql_presto(sql: str) -> Union[pd.DataFrame, None]:
if conn:
try:
sql = sql.rstrip()
# fix for a known problem with presto db where an extra ; will cause an error.
if sql.endswith(';'):
sql = sql[:-1]
cs = conn.cursor()
cs.execute(sql)
results = cs.fetchall()
# Create a pandas dataframe from the results
df = pd.DataFrame(
results, columns=[desc[0] for desc in cs.description]
)
return df
except presto.Error as e:
print(e)
raise ValidationError(e)
except Exception as e:
print(e)
raise e
self.run_sql_is_set = True
self.run_sql = run_sql_presto
def connect_to_hive(
self,
host: str = None,
dbname: str = 'default',
user: str = None,
password: str = None,
port: int = None,
auth: str = 'CUSTOM',
**kwargs
):
"""
Connect to a Hive database. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
Connect to a Hive database. This is just a helper function to set [`vn.run_sql`][vanna.base.base.VannaBase.run_sql]
Args:
host (str): The host of the Hive database.
dbname (str): The name of the database to connect to.
user (str): The username to use for authentication.
password (str): The password to use for authentication.
port (int): The port to use for the connection.
auth (str): The authentication method to use.
Returns:
None
"""
try:
from pyhive import hive
except ImportError:
raise DependencyError(
"You need to install required dependencies to execute this method,"
" run command: \npip install pyhive"
)
if not host:
host = os.getenv("HIVE_HOST")
if not host:
raise ImproperlyConfigured("Please set your hive host")
if not dbname:
dbname = os.getenv("HIVE_DATABASE")
if not dbname:
raise ImproperlyConfigured("Please set your hive database")
if not user:
user = os.getenv("HIVE_USER")
if not user:
raise ImproperlyConfigured("Please set your hive user")
if not password:
password = os.getenv("HIVE_PASSWORD")
if not port:
port = os.getenv("HIVE_PORT")
if not port:
raise ImproperlyConfigured("Please set your hive port")
conn = None
try:
conn = hive.Connection(host=host,
username=user,
password=password,
database=dbname,
port=port,
auth=auth)
except hive.Error as e:
raise ValidationError(e)
def run_sql_hive(sql: str) -> Union[pd.DataFrame, None]:
if conn:
try:
cs = conn.cursor()
cs.execute(sql)
results = cs.fetchall()
# Create a pandas dataframe from the results
df = pd.DataFrame(
results, columns=[desc[0] for desc in cs.description]
)
return df
except hive.Error as e:
print(e)
raise ValidationError(e)
except Exception as e:
print(e)
raise e
self.run_sql_is_set = True
self.run_sql = run_sql_hive
def run_sql(self, sql: str, **kwargs) -> pd.DataFrame:
"""
Example:
\`\`\`python
vn.run_sql("SELECT * FROM my_table")
\`\`\`
Run a SQL query on the connected database.
Args:
sql (str): The SQL query to run.
Returns:
pd.DataFrame: The results of the SQL query.
"""
raise Exception(
"You need to connect to a database first by running vn.connect_to_snowflake(), vn.connect_to_postgres(), similar function, or manually set vn.run_sql"
)
def ask(
self,
question: Union[str, None] = None,
print_results: bool = True,
auto_train: bool = True,
visualize: bool = True, # if False, will not generate plotly code
allow_llm_to_see_data: bool = False,
) -> Union[
Tuple[
Union[str, None],
Union[pd.DataFrame, None],
Union[plotly.graph_objs.Figure, None],
],
None,
]:
"""
**Example:**
\`\`\`python
vn.ask("What are the top 10 customers by sales?")
\`\`\`
Ask Vanna.AI a question and get the SQL query that answers it.
Args:
question (str): The question to ask.
print_results (bool): Whether to print the results of the SQL query.
auto_train (bool): Whether to automatically train Vanna.AI on the question and SQL query.
visualize (bool): Whether to generate plotly code and display the plotly figure.
Returns:
Tuple[str, pd.DataFrame, plotly.graph_objs.Figure]: The SQL query, the results of the SQL query, and the plotly figure.
"""
if question is None:
question = input("Enter a question: ")
try:
sql = self.generate_sql(question=question, allow_llm_to_see_data=allow_llm_to_see_data)
except Exception as e:
print(e)
return None, None, None
if print_results:
try:
Code = __import__("IPython.display", fromList=["Code"]).Code
display(Code(sql))
except Exception as e:
print(sql)
if self.run_sql_is_set is False:
print(
"If you want to run the SQL query, connect to a database first."
)
if print_results:
return None
else:
return sql, None, None
try:
df = self.run_sql(sql)
if print_results:
try:
display = __import__(
"IPython.display", fromList=["display"]
).display
display(df)
except Exception as e:
print(df)
if len(df) > 0 and auto_train:
self.add_question_sql(question=question, sql=sql)
# Only generate plotly code if visualize is True
if visualize:
try:
plotly_code = self.generate_plotly_code(
question=question,
sql=sql,
df_metadata=f"Running df.dtypes gives:\n {df.dtypes}",
)
fig = self.get_plotly_figure(plotly_code=plotly_code, df=df)
if print_results:
try:
display = __import__(
"IPython.display", fromlist=["display"]
).display
Image = __import__(
"IPython.display", fromlist=["Image"]
).Image
img_bytes = fig.to_image(format="png", scale=2)
display(Image(img_bytes))
except Exception as e:
fig.show()
except Exception as e:
# Print stack trace
traceback.print_exc()
print("Couldn't run plotly code: ", e)
if print_results:
return None
else:
return sql, df, None
else:
return sql, df, None
except Exception as e:
print("Couldn't run sql: ", e)
if print_results:
return None
else:
return sql, None, None
return sql, df, fig
def train(
self,
question: str = None,
sql: str = None,
ddl: str = None,
documentation: str = None,
plan: TrainingPlan = None,
) -> str:
"""
**Example:**
\`\`\`python
vn.train()
\`\`\`
Train Vanna.AI on a question and its corresponding SQL query.
If you call it with no arguments, it will check if you connected to a database and it will attempt to train on the metadata of that database.
If you call it with the sql argument, it's equivalent to [`vn.add_question_sql()`][vanna.base.base.VannaBase.add_question_sql].
If you call it with the ddl argument, it's equivalent to [`vn.add_ddl()`][vanna.base.base.VannaBase.add_ddl].
If you call it with the documentation argument, it's equivalent to [`vn.add_documentation()`][vanna.base.base.VannaBase.add_documentation].
Additionally, you can pass a [`TrainingPlan`][vanna.types.TrainingPlan] object. Get a training plan with [`vn.get_training_plan_generic()`][vanna.base.base.VannaBase.get_training_plan_generic].
Args:
question (str): The question to train on.
sql (str): The SQL query to train on.
ddl (str): The DDL statement.
documentation (str): The documentation to train on.
plan (TrainingPlan): The training plan to train on.
"""
if question and not sql:
raise ValidationError("Please also provide a SQL query")
if documentation:
print("Adding documentation....")
return self.add_documentation(documentation)
if sql:
if question is None:
question = self.generate_question(sql)
print("Question generated with sql:", question, "\nAdding SQL...")
return self.add_question_sql(question=question, sql=sql)
if ddl:
print("Adding ddl:", ddl)
return self.add_ddl(ddl)
if plan:
for item in plan._plan:
if item.item_type == TrainingPlanItem.ITEM_TYPE_DDL:
self.add_ddl(item.item_value)
elif item.item_type == TrainingPlanItem.ITEM_TYPE_IS:
self.add_documentation(item.item_value)
elif item.item_type == TrainingPlanItem.ITEM_TYPE_SQL:
self.add_question_sql(question=item.item_name, sql=item.item_value)
def _get_databases(self) -> List[str]:
try:
print("Trying INFORMATION_SCHEMA.DATABASES")
df_databases = self.run_sql("SELECT * FROM INFORMATION_SCHEMA.DATABASES")
except Exception as e:
print(e)
try:
print("Trying SHOW DATABASES")
df_databases = self.run_sql("SHOW DATABASES")
except Exception as e:
print(e)
return []
return df_databases["DATABASE_NAME"].unique().tolist()
def _get_information_schema_tables(self, database: str) -> pd.DataFrame:
df_tables = self.run_sql(f"SELECT * FROM {database}.INFORMATION_SCHEMA.TABLES")
return df_tables
def get_training_plan_generic(self, df) -> TrainingPlan:
"""
This method is used to generate a training plan from an information schema dataframe.
Basically what it does is breaks up INFORMATION_SCHEMA.COLUMNS into groups of table/column descriptions that can be used to pass to the LLM.
Args:
df (pd.DataFrame): The dataframe to generate the training plan from.
Returns:
TrainingPlan: The training plan.
"""
# For each of the following, we look at the df columns to see if there's a match:
database_column = df.columns[
df.columns.str.lower().str.contains("database")
| df.columns.str.lower().str.contains("table_catalog")
].to_list()[0]
schema_column = df.columns[
df.columns.str.lower().str.contains("table_schema")
].to_list()[0]
table_column = df.columns[
df.columns.str.lower().str.contains("table_name")
].to_list()[0]
columns = [database_column,
schema_column,
table_column]
candidates = ["column_name",
"data_type",
"comment"]
matches = df.columns.str.lower().str.contains("|".join(candidates), regex=True)
columns += df.columns[matches].to_list()
plan = TrainingPlan([])
for database in df[database_column].unique().tolist():
for schema in (
df.query(f'{database_column} == "{database}"')[schema_column]
.unique()
.tolist()
):
for table in (
df.query(
f'{database_column} == "{database}" and {schema_column} == "{schema}"'
)[table_column]
.unique()
.tolist()
):
df_columns_filtered_to_table = df.query(
f'{database_column} == "{database}" and {schema_column} == "{schema}" and {table_column} == "{table}"'
)
doc = f"The following columns are in the {table} table in the {database} database:\n\n"
doc += df_columns_filtered_to_table[columns].to_markdown()
plan._plan.append(
TrainingPlanItem(
item_type=TrainingPlanItem.ITEM_TYPE_IS,
item_group=f"{database}.{schema}",
item_name=table,
item_value=doc,
)
)
return plan
def get_training_plan_snowflake(
self,
filter_databases: Union[List[str], None] = None,
filter_schemas: Union[List[str], None] = None,
include_information_schema: bool = False,
use_historical_queries: bool = True,
) -> TrainingPlan:
plan = TrainingPlan([])
if self.run_sql_is_set is False:
raise ImproperlyConfigured("Please connect to a database first.")
if use_historical_queries:
try:
print("Trying query history")
df_history = self.run_sql(
""" select * from table(information_schema.query_history(result_limit => 5000)) order by start_time"""
)
df_history_filtered = df_history.query("ROWS_PRODUCED > 1")
if filter_databases is not None:
mask = (
df_history_filtered["QUERY_TEXT"]
.str.lower()
.apply(
lambda x: any(
s in x for s in [s.lower() for s in filter_databases]
)
)
)
df_history_filtered = df_history_filtered[mask]
if filter_schemas is not None:
mask = (
df_history_filtered["QUERY_TEXT"]
.str.lower()
.apply(
lambda x: any(
s in x for s in [s.lower() for s in filter_schemas]
)
)
)
df_history_filtered = df_history_filtered[mask]
if len(df_history_filtered) > 10:
df_history_filtered = df_history_filtered.sample(10)
for query in df_history_filtered["QUERY_TEXT"].unique().tolist():
plan._plan.append(
TrainingPlanItem(
item_type=TrainingPlanItem.ITEM_TYPE_SQL,
item_group="",
item_name=self.generate_question(query),
item_value=query,
)
)
except Exception as e:
print(e)
databases = self._get_databases()
for database in databases:
if filter_databases is not None and database not in filter_databases:
continue
try:
df_tables = self._get_information_schema_tables(database=database)
print(f"Trying INFORMATION_SCHEMA.COLUMNS for {database}")
df_columns = self.run_sql(
f"SELECT * FROM {database}.INFORMATION_SCHEMA.COLUMNS"
)
for schema in df_tables["TABLE_SCHEMA"].unique().tolist():
if filter_schemas is not None and schema not in filter_schemas:
continue
if (
not include_information_schema
and schema == "INFORMATION_SCHEMA"
):
continue
df_columns_filtered_to_schema = df_columns.query(
f"TABLE_SCHEMA == '{schema}'"
)
try:
tables = (
df_columns_filtered_to_schema["TABLE_NAME"]
.unique()
.tolist()
)
for table in tables:
df_columns_filtered_to_table = (
df_columns_filtered_to_schema.query(
f"TABLE_NAME == '{table}'"
)
)
doc = f"The following columns are in the {table} table in the {database} database:\n\n"
doc += df_columns_filtered_to_table[
[
"TABLE_CATALOG",
"TABLE_SCHEMA",
"TABLE_NAME",
"COLUMN_NAME",
"DATA_TYPE",
"COMMENT",
]
].to_markdown()
plan._plan.append(
TrainingPlanItem(
item_type=TrainingPlanItem.ITEM_TYPE_IS,
item_group=f"{database}.{schema}",
item_name=table,
item_value=doc,
)
)
except Exception as e:
print(e)
pass
except Exception as e:
print(e)
return plan
def get_plotly_figure(
self, plotly_code: str, df: pd.DataFrame, dark_mode: bool = True
) -> plotly.graph_objs.Figure:
"""
**Example:**
\`\`\`python
fig = vn.get_plotly_figure(
plotly_code="fig = px.bar(df, x='name', y='salary')",
df=df
)
fig.show()
\`\`\`
Get a Plotly figure from a dataframe and Plotly code.
Args:
df (pd.DataFrame): The dataframe to use.
plotly_code (str): The Plotly code to use.
Returns:
plotly.graph_objs.Figure: The Plotly figure.
"""
ldict = {"df": df, "px": px, "go": go}
try:
exec(plotly_code, globals(), ldict)
fig = ldict.get("fig", None)
except Exception as e:
# Inspect data types
numeric_cols = df.select_dtypes(include=["number"]).columns.tolist()
categorical_cols = df.select_dtypes(
include=["object", "category"]
).columns.tolist()
# Decision-making for plot type
if len(numeric_cols) >= 2:
# Use the first two numeric columns for a scatter plot
fig = px.scatter(df, x=numeric_cols[0], y=numeric_cols[1])
elif len(numeric_cols) == 1 and len(categorical_cols) >= 1:
# Use a bar plot if there's one numeric and one categorical column
fig = px.bar(df, x=categorical_cols[0], y=numeric_cols[0])
elif len(categorical_cols) >= 1 and df[categorical_cols[0]].nunique() < 10:
# Use a pie chart for categorical data with fewer unique values
fig = px.pie(df, names=categorical_cols[0])
else:
# Default to a simple line plot if above conditions are not met
fig = px.line(df)
if fig is None:
return None
if dark_mode:
fig.update_layout(template="plotly_dark")
return fig
```
## /src/vanna/bedrock/__init__.py
```py path="/src/vanna/bedrock/__init__.py"
from .bedrock_converse import Bedrock_Converse
```
## /src/vanna/bedrock/bedrock_converse.py
```py path="/src/vanna/bedrock/bedrock_converse.py"
from ..base import VannaBase
try:
import boto3
from botocore.exceptions import ClientError
except ImportError:
raise ImportError("Please install boto3 and botocore to use Amazon Bedrock models")
class Bedrock_Converse(VannaBase):
def __init__(self, client=None, config=None):
VannaBase.__init__(self, config=config)
# default parameters
self.temperature = 0.0
self.max_tokens = 500
if client is None:
raise ValueError(
"A valid Bedrock runtime client must be provided to invoke Bedrock models"
)
else:
self.client = client
if config is None:
raise ValueError(
"Config is required with model_id and inference parameters"
)
if "modelId" not in config:
raise ValueError(
"config must contain a modelId to invoke"
)
else:
self.model = config["modelId"]
if "temperature" in config:
self.temperature = config["temperature"]
if "max_tokens" in config:
self.max_tokens = config["max_tokens"]
def system_message(self, message: str) -> dict:
return {"role": "system", "content": message}
def user_message(self, message: str) -> dict:
return {"role": "user", "content": message}
def assistant_message(self, message: str) -> dict:
return {"role": "assistant", "content": message}
def submit_prompt(self, prompt, **kwargs) -> str:
inference_config = {
"temperature": self.temperature,
"maxTokens": self.max_tokens
}
additional_model_fields = {
"top_p": 1, # setting top_p value for nucleus sampling
}
system_message = None
no_system_prompt = []
for prompt_message in prompt:
role = prompt_message["role"]
if role == "system":
system_message = prompt_message["content"]
else:
no_system_prompt.append({"role": role, "content":[{"text": prompt_message["content"]}]})
converse_api_params = {
"modelId": self.model,
"messages": no_system_prompt,
"inferenceConfig": inference_config,
"additionalModelRequestFields": additional_model_fields
}
if system_message:
converse_api_params["system"] = [{"text": system_message}]
try:
response = self.client.converse(**converse_api_params)
text_content = response["output"]["message"]["content"][0]["text"]
return text_content
except ClientError as err:
message = err.response["Error"]["Message"]
raise Exception(f"A Bedrock client error occurred: {message}")
```
## /src/vanna/chromadb/__init__.py
```py path="/src/vanna/chromadb/__init__.py"
from .chromadb_vector import ChromaDB_VectorStore
```
## /src/vanna/chromadb/chromadb_vector.py
```py path="/src/vanna/chromadb/chromadb_vector.py"
import json
from typing import List
import chromadb
import pandas as pd
from chromadb.config import Settings
from chromadb.utils import embedding_functions
from ..base import VannaBase
from ..utils import deterministic_uuid
default_ef = embedding_functions.DefaultEmbeddingFunction()
class ChromaDB_VectorStore(VannaBase):
def __init__(self, config=None):
VannaBase.__init__(self, config=config)
if config is None:
config = {}
path = config.get("path", ".")
self.embedding_function = config.get("embedding_function", default_ef)
curr_client = config.get("client", "persistent")
collection_metadata = config.get("collection_metadata", None)
self.n_results_sql = config.get("n_results_sql", config.get("n_results", 10))
self.n_results_documentation = config.get("n_results_documentation", config.get("n_results", 10))
self.n_results_ddl = config.get("n_results_ddl", config.get("n_results", 10))
if curr_client == "persistent":
self.chroma_client = chromadb.PersistentClient(
path=path, settings=Settings(anonymized_telemetry=False)
)
elif curr_client == "in-memory":
self.chroma_client = chromadb.EphemeralClient(
settings=Settings(anonymized_telemetry=False)
)
elif isinstance(curr_client, chromadb.api.client.Client):
# allow providing client directly
self.chroma_client = curr_client
else:
raise ValueError(f"Unsupported client was set in config: {curr_client}")
self.documentation_collection = self.chroma_client.get_or_create_collection(
name="documentation",
embedding_function=self.embedding_function,
metadata=collection_metadata,
)
self.ddl_collection = self.chroma_client.get_or_create_collection(
name="ddl",
embedding_function=self.embedding_function,
metadata=collection_metadata,
)
self.sql_collection = self.chroma_client.get_or_create_collection(
name="sql",
embedding_function=self.embedding_function,
metadata=collection_metadata,
)
def generate_embedding(self, data: str, **kwargs) -> List[float]:
embedding = self.embedding_function([data])
if len(embedding) == 1:
return embedding[0]
return embedding
def add_question_sql(self, question: str, sql: str, **kwargs) -> str:
question_sql_json = json.dumps(
{
"question": question,
"sql": sql,
},
ensure_ascii=False,
)
id = deterministic_uuid(question_sql_json) + "-sql"
self.sql_collection.add(
documents=question_sql_json,
embeddings=self.generate_embedding(question_sql_json),
ids=id,
)
return id
def add_ddl(self, ddl: str, **kwargs) -> str:
id = deterministic_uuid(ddl) + "-ddl"
self.ddl_collection.add(
documents=ddl,
embeddings=self.generate_embedding(ddl),
ids=id,
)
return id
def add_documentation(self, documentation: str, **kwargs) -> str:
id = deterministic_uuid(documentation) + "-doc"
self.documentation_collection.add(
documents=documentation,
embeddings=self.generate_embedding(documentation),
ids=id,
)
return id
def get_training_data(self, **kwargs) -> pd.DataFrame:
sql_data = self.sql_collection.get()
df = pd.DataFrame()
if sql_data is not None:
# Extract the documents and ids
documents = [json.loads(doc) for doc in sql_data["documents"]]
ids = sql_data["ids"]
# Create a DataFrame
df_sql = pd.DataFrame(
{
"id": ids,
"question": [doc["question"] for doc in documents],
"content": [doc["sql"] for doc in documents],
}
)
df_sql["training_data_type"] = "sql"
df = pd.concat([df, df_sql])
ddl_data = self.ddl_collection.get()
if ddl_data is not None:
# Extract the documents and ids
documents = [doc for doc in ddl_data["documents"]]
ids = ddl_data["ids"]
# Create a DataFrame
df_ddl = pd.DataFrame(
{
"id": ids,
"question": [None for doc in documents],
"content": [doc for doc in documents],
}
)
df_ddl["training_data_type"] = "ddl"
df = pd.concat([df, df_ddl])
doc_data = self.documentation_collection.get()
if doc_data is not None:
# Extract the documents and ids
documents = [doc for doc in doc_data["documents"]]
ids = doc_data["ids"]
# Create a DataFrame
df_doc = pd.DataFrame(
{
"id": ids,
"question": [None for doc in documents],
"content": [doc for doc in documents],
}
)
df_doc["training_data_type"] = "documentation"
df = pd.concat([df, df_doc])
return df
def remove_training_data(self, id: str, **kwargs) -> bool:
if id.endswith("-sql"):
self.sql_collection.delete(ids=id)
return True
elif id.endswith("-ddl"):
self.ddl_collection.delete(ids=id)
return True
elif id.endswith("-doc"):
self.documentation_collection.delete(ids=id)
return True
else:
return False
def remove_collection(self, collection_name: str) -> bool:
"""
This function can reset the collection to empty state.
Args:
collection_name (str): sql or ddl or documentation
Returns:
bool: True if collection is deleted, False otherwise
"""
if collection_name == "sql":
self.chroma_client.delete_collection(name="sql")
self.sql_collection = self.chroma_client.get_or_create_collection(
name="sql", embedding_function=self.embedding_function
)
return True
elif collection_name == "ddl":
self.chroma_client.delete_collection(name="ddl")
self.ddl_collection = self.chroma_client.get_or_create_collection(
name="ddl", embedding_function=self.embedding_function
)
return True
elif collection_name == "documentation":
self.chroma_client.delete_collection(name="documentation")
self.documentation_collection = self.chroma_client.get_or_create_collection(
name="documentation", embedding_function=self.embedding_function
)
return True
else:
return False
@staticmethod
def _extract_documents(query_results) -> list:
"""
Static method to extract the documents from the results of a query.
Args:
query_results (pd.DataFrame): The dataframe to use.
Returns:
List[str] or None: The extracted documents, or an empty list or
single document if an error occurred.
"""
if query_results is None:
return []
if "documents" in query_results:
documents = query_results["documents"]
if len(documents) == 1 and isinstance(documents[0], list):
try:
documents = [json.loads(doc) for doc in documents[0]]
except Exception as e:
return documents[0]
return documents
def get_similar_question_sql(self, question: str, **kwargs) -> list:
return ChromaDB_VectorStore._extract_documents(
self.sql_collection.query(
query_texts=[question],
n_results=self.n_results_sql,
)
)
def get_related_ddl(self, question: str, **kwargs) -> list:
return ChromaDB_VectorStore._extract_documents(
self.ddl_collection.query(
query_texts=[question],
n_results=self.n_results_ddl,
)
)
def get_related_documentation(self, question: str, **kwargs) -> list:
return ChromaDB_VectorStore._extract_documents(
self.documentation_collection.query(
query_texts=[question],
n_results=self.n_results_documentation,
)
)
```
## /src/vanna/cohere/__init__.py
```py path="/src/vanna/cohere/__init__.py"
from .cohere_chat import Cohere_Chat
from .cohere_embeddings import Cohere_Embeddings
```
## /src/vanna/cohere/cohere_chat.py
```py path="/src/vanna/cohere/cohere_chat.py"
import os
from openai import OpenAI
from ..base import VannaBase
class Cohere_Chat(VannaBase):
def __init__(self, client=None, config=None):
VannaBase.__init__(self, config=config)
# default parameters - can be overridden using config
self.temperature = 0.2 # Lower temperature for more precise SQL generation
self.model = "command-a-03-2025" # Cohere's default model
if config is not None:
if "temperature" in config:
self.temperature = config["temperature"]
if "model" in config:
self.model = config["model"]
if client is not None:
self.client = client
return
# Check for API key in environment variable
api_key = os.getenv("COHERE_API_KEY")
# Check for API key in config
if config is not None and "api_key" in config:
api_key = config["api_key"]
# Validate API key
if not api_key:
raise ValueError("Cohere API key is required. Please provide it via config or set the COHERE_API_KEY environment variable.")
# Initialize client with validated API key
self.client = OpenAI(
base_url="https://api.cohere.ai/compatibility/v1",
api_key=api_key,
)
def system_message(self, message: str) -> any:
return {"role": "developer", "content": message} # Cohere uses 'developer' for system role
def user_message(self, message: str) -> any:
return {"role": "user", "content": message}
def assistant_message(self, message: str) -> any:
return {"role": "assistant", "content": message}
def submit_prompt(self, prompt, **kwargs) -> str:
if prompt is None:
raise Exception("Prompt is None")
if len(prompt) == 0:
raise Exception("Prompt is empty")
# Count the number of tokens in the message log
# Use 4 as an approximation for the number of characters per token
num_tokens = 0
for message in prompt:
num_tokens += len(message["content"]) / 4
# Use model from kwargs, config, or default
model = kwargs.get("model", self.model)
if self.config is not None and "model" in self.config and model == self.model:
model = self.config["model"]
print(f"Using model {model} for {num_tokens} tokens (approx)")
try:
response = self.client.chat.completions.create(
model=model,
messages=prompt,
temperature=self.temperature,
)
# Check if response has expected structure
if not response or not hasattr(response, 'choices') or not response.choices:
raise ValueError("Received empty or malformed response from API")
if not response.choices[0] or not hasattr(response.choices[0], 'message'):
raise ValueError("Response is missing expected 'message' field")
if not hasattr(response.choices[0].message, 'content'):
raise ValueError("Response message is missing expected 'content' field")
return response.choices[0].message.content
except Exception as e:
# Log the error and raise a more informative exception
error_msg = f"Error processing Cohere chat response: {str(e)}"
print(error_msg)
raise Exception(error_msg)
```
## /src/vanna/cohere/cohere_embeddings.py
```py path="/src/vanna/cohere/cohere_embeddings.py"
import os
from openai import OpenAI
from ..base import VannaBase
class Cohere_Embeddings(VannaBase):
def __init__(self, client=None, config=None):
VannaBase.__init__(self, config=config)
# Default embedding model
self.model = "embed-multilingual-v3.0"
if config is not None and "model" in config:
self.model = config["model"]
if client is not None:
self.client = client
return
# Check for API key in environment variable
api_key = os.getenv("COHERE_API_KEY")
# Check for API key in config
if config is not None and "api_key" in config:
api_key = config["api_key"]
# Validate API key
if not api_key:
raise ValueError("Cohere API key is required. Please provide it via config or set the COHERE_API_KEY environment variable.")
# Initialize client with validated API key
self.client = OpenAI(
base_url="https://api.cohere.ai/compatibility/v1",
api_key=api_key,
)
def generate_embedding(self, data: str, **kwargs) -> list[float]:
if not data:
raise ValueError("Cannot generate embedding for empty input data")
# Use model from kwargs, config, or default
model = kwargs.get("model", self.model)
if self.config is not None and "model" in self.config and model == self.model:
model = self.config["model"]
try:
embedding = self.client.embeddings.create(
model=model,
input=data,
encoding_format="float", # Ensure we get float values
)
# Check if response has expected structure
if not embedding or not hasattr(embedding, 'data') or not embedding.data:
raise ValueError("Received empty or malformed embedding response from API")
if not embedding.data[0] or not hasattr(embedding.data[0], 'embedding'):
raise ValueError("Embedding response is missing expected 'embedding' field")
if not embedding.data[0].embedding:
raise ValueError("Received empty embedding vector")
return embedding.data[0].embedding
except Exception as e:
# Log the error and raise a more informative exception
error_msg = f"Error generating embedding with Cohere: {str(e)}"
print(error_msg)
raise Exception(error_msg)
```
## /src/vanna/deepseek/__init__.py
```py path="/src/vanna/deepseek/__init__.py"
from .deepseek_chat import DeepSeekChat
```
## /src/vanna/deepseek/deepseek_chat.py
```py path="/src/vanna/deepseek/deepseek_chat.py"
import os
from openai import OpenAI
from ..base import VannaBase
# from vanna.chromadb import ChromaDB_VectorStore
# class DeepSeekVanna(ChromaDB_VectorStore, DeepSeekChat):
# def __init__(self, config=None):
# ChromaDB_VectorStore.__init__(self, config=config)
# DeepSeekChat.__init__(self, config=config)
# vn = DeepSeekVanna(config={"api_key": "sk-************", "model": "deepseek-chat"})
class DeepSeekChat(VannaBase):
def __init__(self, config=None):
if config is None:
raise ValueError(
"For DeepSeek, config must be provided with an api_key and model"
)
if "api_key" not in config:
raise ValueError("config must contain a DeepSeek api_key")
if "model" not in config:
raise ValueError("config must contain a DeepSeek model")
api_key = config["api_key"]
model = config["model"]
self.model = model
self.client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com/v1")
def system_message(self, message: str) -> any:
return {"role": "system", "content": message}
def user_message(self, message: str) -> any:
return {"role": "user", "content": message}
def assistant_message(self, message: str) -> any:
return {"role": "assistant", "content": message}
def generate_sql(self, question: str, **kwargs) -> str:
# 使用父类的 generate_sql
sql = super().generate_sql(question, **kwargs)
# 替换 "\_" 为 "_"
sql = sql.replace("\\_", "_")
return sql
def submit_prompt(self, prompt, **kwargs) -> str:
chat_response = self.client.chat.completions.create(
model=self.model,
messages=prompt,
)
return chat_response.choices[0].message.content
```
## /src/vanna/exceptions/__init__.py
```py path="/src/vanna/exceptions/__init__.py"
class ImproperlyConfigured(Exception):
"""Raise for incorrect configuration."""
pass
class DependencyError(Exception):
"""Raise for missing dependencies."""
pass
class ConnectionError(Exception):
"""Raise for connection"""
pass
class OTPCodeError(Exception):
"""Raise for invalid otp or not able to send it"""
pass
class SQLRemoveError(Exception):
"""Raise when not able to remove SQL"""
pass
class ExecutionError(Exception):
"""Raise when not able to execute Code"""
pass
class ValidationError(Exception):
"""Raise for validations"""
pass
class APIError(Exception):
"""Raise for API errors"""
pass
```
## /src/vanna/faiss/__init__.py
```py path="/src/vanna/faiss/__init__.py"
from .faiss import FAISS
```
## /src/vanna/faiss/faiss.py
```py path="/src/vanna/faiss/faiss.py"
import os
import json
import uuid
from typing import List, Dict, Any
import faiss
import numpy as np
import pandas as pd
from ..base import VannaBase
from ..exceptions import DependencyError
class FAISS(VannaBase):
def __init__(self, config=None):
if config is None:
config = {}
VannaBase.__init__(self, config=config)
try:
import faiss
except ImportError:
raise DependencyError(
"FAISS is not installed. Please install it with 'pip install faiss-cpu' or 'pip install faiss-gpu'"
)
try:
from sentence_transformers import SentenceTransformer
except ImportError:
raise DependencyError(
"SentenceTransformer is not installed. Please install it with 'pip install sentence-transformers'."
)
self.path = config.get("path", ".")
self.embedding_dim = config.get('embedding_dim', 384)
self.n_results_sql = config.get('n_results_sql', config.get("n_results", 10))
self.n_results_ddl = config.get('n_results_ddl', config.get("n_results", 10))
self.n_results_documentation = config.get('n_results_documentation', config.get("n_results", 10))
self.curr_client = config.get("client", "persistent")
if self.curr_client == 'persistent':
self.sql_index = self._load_or_create_index('sql_index.faiss')
self.ddl_index = self._load_or_create_index('ddl_index.faiss')
self.doc_index = self._load_or_create_index('doc_index.faiss')
elif self.curr_client == 'in-memory':
self.sql_index = faiss.IndexFlatL2(self.embedding_dim)
self.ddl_index = faiss.IndexFlatL2(self.embedding_dim)
self.doc_index = faiss.IndexFlatL2(self.embedding_dim)
elif isinstance(self.curr_client, list) and len(self.curr_client) == 3 and all(isinstance(idx, faiss.Index) for idx in self.curr_client):
self.sql_index = self.curr_client[0]
self.ddl_index = self.curr_client[1]
self.doc_index = self.curr_client[2]
else:
raise ValueError(f"Unsupported storage type was set in config: {self.curr_client}")
self.sql_metadata: List[Dict[str, Any]] = self._load_or_create_metadata('sql_metadata.json')
self.ddl_metadata: List[Dict[str, str]] = self._load_or_create_metadata('ddl_metadata.json')
self.doc_metadata: List[Dict[str, str]] = self._load_or_create_metadata('doc_metadata.json')
model_name = config.get('embedding_model', 'all-MiniLM-L6-v2')
self.embedding_model = SentenceTransformer(model_name)
def _load_or_create_index(self, filename):
filepath = os.path.join(self.path, filename)
if os.path.exists(filepath):
return faiss.read_index(filepath)
return faiss.IndexFlatL2(self.embedding_dim)
def _load_or_create_metadata(self, filename):
filepath = os.path.join(self.path, filename)
if os.path.exists(filepath):
with open(filepath, 'r') as f:
return json.load(f)
return []
def _save_index(self, index, filename):
if self.curr_client == 'persistent':
filepath = os.path.join(self.path, filename)
faiss.write_index(index, filepath)
def _save_metadata(self, metadata, filename):
if self.curr_client == 'persistent':
filepath = os.path.join(self.path, filename)
with open(filepath, 'w') as f:
json.dump(metadata, f)
def generate_embedding(self, data: str, **kwargs) -> List[float]:
embedding = self.embedding_model.encode(data)
assert embedding.shape[0] == self.embedding_dim, \
f"Embedding dimension mismatch: expected {self.embedding_dim}, got {embedding.shape[0]}"
return embedding.tolist()
def _add_to_index(self, index, metadata_list, text, extra_metadata=None) -> str:
embedding = self.generate_embedding(text)
index.add(np.array([embedding], dtype=np.float32))
entry_id = str(uuid.uuid4())
metadata_list.append({"id": entry_id, **(extra_metadata or {})})
return entry_id
def add_question_sql(self, question: str, sql: str, **kwargs) -> str:
entry_id = self._add_to_index(self.sql_index, self.sql_metadata, question + " " + sql, {"question": question, "sql": sql})
self._save_index(self.sql_index, 'sql_index.faiss')
self._save_metadata(self.sql_metadata, 'sql_metadata.json')
return entry_id
def add_ddl(self, ddl: str, **kwargs) -> str:
entry_id = self._add_to_index(self.ddl_index, self.ddl_metadata, ddl, {"ddl": ddl})
self._save_index(self.ddl_index, 'ddl_index.faiss')
self._save_metadata(self.ddl_metadata, 'ddl_metadata.json')
return entry_id
def add_documentation(self, documentation: str, **kwargs) -> str:
entry_id = self._add_to_index(self.doc_index, self.doc_metadata, documentation, {"documentation": documentation})
self._save_index(self.doc_index, 'doc_index.faiss')
self._save_metadata(self.doc_metadata, 'doc_metadata.json')
return entry_id
def _get_similar(self, index, metadata_list, text, n_results) -> list:
embedding = self.generate_embedding(text)
D, I = index.search(np.array([embedding], dtype=np.float32), k=n_results)
return [] if len(I[0]) == 0 or I[0][0] == -1 else [metadata_list[i] for i in I[0]]
def get_similar_question_sql(self, question: str, **kwargs) -> list:
return self._get_similar(self.sql_index, self.sql_metadata, question, self.n_results_sql)
def get_related_ddl(self, question: str, **kwargs) -> list:
return [metadata["ddl"] for metadata in self._get_similar(self.ddl_index, self.ddl_metadata, question, self.n_results_ddl)]
def get_related_documentation(self, question: str, **kwargs) -> list:
return [metadata["documentation"] for metadata in self._get_similar(self.doc_index, self.doc_metadata, question, self.n_results_documentation)]
def get_training_data(self, **kwargs) -> pd.DataFrame:
sql_data = pd.DataFrame(self.sql_metadata)
sql_data['training_data_type'] = 'sql'
ddl_data = pd.DataFrame(self.ddl_metadata)
ddl_data['training_data_type'] = 'ddl'
doc_data = pd.DataFrame(self.doc_metadata)
doc_data['training_data_type'] = 'documentation'
return pd.concat([sql_data, ddl_data, doc_data], ignore_index=True)
def remove_training_data(self, id: str, **kwargs) -> bool:
for metadata_list, index, index_name in [
(self.sql_metadata, self.sql_index, 'sql_index.faiss'),
(self.ddl_metadata, self.ddl_index, 'ddl_index.faiss'),
(self.doc_metadata, self.doc_index, 'doc_index.faiss')
]:
for i, item in enumerate(metadata_list):
if item['id'] == id:
del metadata_list[i]
new_index = faiss.IndexFlatL2(self.embedding_dim)
embeddings = [self.generate_embedding(json.dumps(m)) for m in metadata_list]
if embeddings:
new_index.add(np.array(embeddings, dtype=np.float32))
setattr(self, index_name.split('.')[0], new_index)
if self.curr_client == 'persistent':
self._save_index(new_index, index_name)
self._save_metadata(metadata_list, f"{index_name.split('.')[0]}_metadata.json")
return True
return False
def remove_collection(self, collection_name: str) -> bool:
if collection_name in ["sql", "ddl", "documentation"]:
setattr(self, f"{collection_name}_index", faiss.IndexFlatL2(self.embedding_dim))
setattr(self, f"{collection_name}_metadata", [])
if self.curr_client == 'persistent':
self._save_index(getattr(self, f"{collection_name}_index"), f"{collection_name}_index.faiss")
self._save_metadata([], f"{collection_name}_metadata.json")
return True
return False
```
## /src/vanna/flask/__init__.py
```py path="/src/vanna/flask/__init__.py"
import json
import logging
import os
import sys
import uuid
from abc import ABC, abstractmethod
from functools import wraps
import importlib.metadata
import flask
import requests
from flasgger import Swagger
from flask import Flask, Response, jsonify, request, send_from_directory
from flask_sock import Sock
from ..base import VannaBase
from .assets import css_content, html_content, js_content
from .auth import AuthInterface, NoAuth
class Cache(ABC):
"""
Define the interface for a cache that can be used to store data in a Flask app.
"""
@abstractmethod
def generate_id(self, *args, **kwargs):
"""
Generate a unique ID for the cache.
"""
pass
@abstractmethod
def get(self, id, field):
"""
Get a value from the cache.
"""
pass
@abstractmethod
def get_all(self, field_list) -> list:
"""
Get all values from the cache.
"""
pass
@abstractmethod
def set(self, id, field, value):
"""
Set a value in the cache.
"""
pass
@abstractmethod
def delete(self, id):
"""
Delete a value from the cache.
"""
pass
class MemoryCache(Cache):
def __init__(self):
self.cache = {}
def generate_id(self, *args, **kwargs):
return str(uuid.uuid4())
def set(self, id, field, value):
if id not in self.cache:
self.cache[id] = {}
self.cache[id][field] = value
def get(self, id, field):
if id not in self.cache:
return None
if field not in self.cache[id]:
return None
return self.cache[id][field]
def get_all(self, field_list) -> list:
return [
{"id": id, **{field: self.get(id=id, field=field) for field in field_list}}
for id in self.cache
]
def delete(self, id):
if id in self.cache:
del self.cache[id]
class VannaFlaskAPI:
flask_app = None
def requires_cache(self, required_fields, optional_fields=[]):
def decorator(f):
@wraps(f)
def decorated(*args, **kwargs):
id = request.args.get("id")
if id is None:
id = request.json.get("id")
if id is None:
return jsonify({"type": "error", "error": "No id provided"})
for field in required_fields:
if self.cache.get(id=id, field=field) is None:
return jsonify({"type": "error", "error": f"No {field} found"})
field_values = {
field: self.cache.get(id=id, field=field) for field in required_fields
}
for field in optional_fields:
field_values[field] = self.cache.get(id=id, field=field)
# Add the id to the field_values
field_values["id"] = id
return f(*args, **field_values, **kwargs)
return decorated
return decorator
def requires_auth(self, f):
@wraps(f)
def decorated(*args, **kwargs):
user = self.auth.get_user(flask.request)
if not self.auth.is_logged_in(user):
return jsonify({"type": "not_logged_in", "html": self.auth.login_form()})
# Pass the user to the function
return f(*args, user=user, **kwargs)
return decorated
def __init__(
self,
vn: VannaBase,
cache: Cache = MemoryCache(),
auth: AuthInterface = NoAuth(),
debug=True,
allow_llm_to_see_data=False,
chart=True,
):
"""
Expose a Flask API that can be used to interact with a Vanna instance.
Args:
vn: The Vanna instance to interact with.
cache: The cache to use. Defaults to MemoryCache, which uses an in-memory cache. You can also pass in a custom cache that implements the Cache interface.
auth: The authentication method to use. Defaults to NoAuth, which doesn't require authentication. You can also pass in a custom authentication method that implements the AuthInterface interface.
debug: Show the debug console. Defaults to True.
allow_llm_to_see_data: Whether to allow the LLM to see data. Defaults to False.
chart: Whether to show the chart output in the UI. Defaults to True.
Returns:
None
"""
self.flask_app = Flask(__name__)
self.swagger = Swagger(
self.flask_app, template={"info": {"title": "Vanna API"}}
)
self.sock = Sock(self.flask_app)
self.ws_clients = []
self.vn = vn
self.auth = auth
self.cache = cache
self.debug = debug
self.allow_llm_to_see_data = allow_llm_to_see_data
self.chart = chart
self.config = {
"debug": debug,
"allow_llm_to_see_data": allow_llm_to_see_data,
"chart": chart,
}
log = logging.getLogger("werkzeug")
log.setLevel(logging.ERROR)
if "google.colab" in sys.modules:
self.debug = False
print("Google Colab doesn't support running websocket servers. Disabling debug mode.")
if self.debug:
def log(message, title="Info"):
[ws.send(json.dumps({'message': message, 'title': title})) for ws in self.ws_clients]
self.vn.log = log
@self.flask_app.route("/api/v0/get_config", methods=["GET"])
@self.requires_auth
def get_config(user: any):
"""
Get the configuration for a user
---
parameters:
- name: user
in: query
responses:
200:
schema:
type: object
properties:
type:
type: string
default: config
config:
type: object
"""
config = self.auth.override_config_for_user(user, self.config)
return jsonify(
{
"type": "config",
"config": config
}
)
@self.flask_app.route("/api/v0/generate_questions", methods=["GET"])
@self.requires_auth
def generate_questions(user: any):
"""
Generate questions
---
parameters:
- name: user
in: query
responses:
200:
schema:
type: object
properties:
type:
type: string
default: question_list
questions:
type: array
items:
type: string
header:
type: string
default: Here are some questions you can ask
"""
# If self has an _model attribute and model=='chinook'
if hasattr(self.vn, "_model") and self.vn._model == "chinook":
return jsonify(
{
"type": "question_list",
"questions": [
"What are the top 10 artists by sales?",
"What are the total sales per year by country?",
"Who is the top selling artist in each genre? Show the sales numbers.",
"How do the employees rank in terms of sales performance?",
"Which 5 cities have the most customers?",
],
"header": "Here are some questions you can ask:",
}
)
training_data = vn.get_training_data()
# If training data is None or empty
if training_data is None or len(training_data) == 0:
return jsonify(
{
"type": "error",
"error": "No training data found. Please add some training data first.",
}
)
# Get the questions from the training data
try:
# Filter training data to only include questions where the question is not null
questions = (
training_data[training_data["question"].notnull()]
.sample(5)["question"]
.tolist()
)
# Temporarily this will just return an empty list
return jsonify(
{
"type": "question_list",
"questions": questions,
"header": "Here are some questions you can ask",
}
)
except Exception as e:
return jsonify(
{
"type": "question_list",
"questions": [],
"header": "Go ahead and ask a question",
}
)
@self.flask_app.route("/api/v0/generate_sql", methods=["GET"])
@self.requires_auth
def generate_sql(user: any):
"""
Generate SQL from a question
---
parameters:
- name: user
in: query
- name: question
in: query
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: sql
id:
type: string
text:
type: string
"""
question = flask.request.args.get("question")
if question is None:
return jsonify({"type": "error", "error": "No question provided"})
id = self.cache.generate_id(question=question)
sql = vn.generate_sql(question=question, allow_llm_to_see_data=self.allow_llm_to_see_data)
self.cache.set(id=id, field="question", value=question)
self.cache.set(id=id, field="sql", value=sql)
if vn.is_sql_valid(sql=sql):
return jsonify(
{
"type": "sql",
"id": id,
"text": sql,
}
)
else:
return jsonify(
{
"type": "text",
"id": id,
"text": sql,
}
)
@self.flask_app.route("/api/v0/generate_rewritten_question", methods=["GET"])
@self.requires_auth
def generate_rewritten_question(user: any):
"""
Generate a rewritten question
---
parameters:
- name: last_question
in: query
type: string
required: true
- name: new_question
in: query
type: string
required: true
"""
last_question = flask.request.args.get("last_question")
new_question = flask.request.args.get("new_question")
rewritten_question = self.vn.generate_rewritten_question(last_question, new_question)
return jsonify({"type": "rewritten_question", "question": rewritten_question})
@self.flask_app.route("/api/v0/get_function", methods=["GET"])
@self.requires_auth
def get_function(user: any):
"""
Get a function from a question
---
parameters:
- name: user
in: query
- name: question
in: query
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: function
id:
type: object
function:
type: string
"""
question = flask.request.args.get("question")
if question is None:
return jsonify({"type": "error", "error": "No question provided"})
if not hasattr(vn, "get_function"):
return jsonify({"type": "error", "error": "This setup does not support function generation."})
id = self.cache.generate_id(question=question)
function = vn.get_function(question=question)
if function is None:
return jsonify({"type": "error", "error": "No function found"})
if 'instantiated_sql' not in function:
self.vn.log(f"No instantiated SQL found for {question} in {function}")
return jsonify({"type": "error", "error": "No instantiated SQL found"})
self.cache.set(id=id, field="question", value=question)
self.cache.set(id=id, field="sql", value=function['instantiated_sql'])
if 'instantiated_post_processing_code' in function and function['instantiated_post_processing_code'] is not None and len(function['instantiated_post_processing_code']) > 0:
self.cache.set(id=id, field="plotly_code", value=function['instantiated_post_processing_code'])
return jsonify(
{
"type": "function",
"id": id,
"function": function,
}
)
@self.flask_app.route("/api/v0/get_all_functions", methods=["GET"])
@self.requires_auth
def get_all_functions(user: any):
"""
Get all the functions
---
parameters:
- name: user
in: query
responses:
200:
schema:
type: object
properties:
type:
type: string
default: functions
functions:
type: array
"""
if not hasattr(vn, "get_all_functions"):
return jsonify({"type": "error", "error": "This setup does not support function generation."})
functions = vn.get_all_functions()
return jsonify(
{
"type": "functions",
"functions": functions,
}
)
@self.flask_app.route("/api/v0/run_sql", methods=["GET"])
@self.requires_auth
@self.requires_cache(["sql"])
def run_sql(user: any, id: str, sql: str):
"""
Run SQL
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: df
id:
type: string
df:
type: object
should_generate_chart:
type: boolean
"""
try:
if not vn.run_sql_is_set:
return jsonify(
{
"type": "error",
"error": "Please connect to a database using vn.connect_to_... in order to run SQL queries.",
}
)
df = vn.run_sql(sql=sql)
self.cache.set(id=id, field="df", value=df)
return jsonify(
{
"type": "df",
"id": id,
"df": df.head(10).to_json(orient='records', date_format='iso'),
"should_generate_chart": self.chart and vn.should_generate_chart(df),
}
)
except Exception as e:
return jsonify({"type": "sql_error", "error": str(e)})
@self.flask_app.route("/api/v0/fix_sql", methods=["POST"])
@self.requires_auth
@self.requires_cache(["question", "sql"])
def fix_sql(user: any, id: str, question: str, sql: str):
"""
Fix SQL
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
- name: error
in: body
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: sql
id:
type: string
text:
type: string
"""
error = flask.request.json.get("error")
if error is None:
return jsonify({"type": "error", "error": "No error provided"})
question = f"I have an error: {error}\n\nHere is the SQL I tried to run: {sql}\n\nThis is the question I was trying to answer: {question}\n\nCan you rewrite the SQL to fix the error?"
fixed_sql = vn.generate_sql(question=question)
self.cache.set(id=id, field="sql", value=fixed_sql)
return jsonify(
{
"type": "sql",
"id": id,
"text": fixed_sql,
}
)
@self.flask_app.route('/api/v0/update_sql', methods=['POST'])
@self.requires_auth
@self.requires_cache([])
def update_sql(user: any, id: str):
"""
Update SQL
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
- name: sql
in: body
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: sql
id:
type: string
text:
type: string
"""
sql = flask.request.json.get('sql')
if sql is None:
return jsonify({"type": "error", "error": "No sql provided"})
self.cache.set(id=id, field='sql', value=sql)
return jsonify(
{
"type": "sql",
"id": id,
"text": sql,
})
@self.flask_app.route("/api/v0/download_csv", methods=["GET"])
@self.requires_auth
@self.requires_cache(["df"])
def download_csv(user: any, id: str, df):
"""
Download CSV
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
responses:
200:
description: download CSV
"""
csv = df.to_csv()
return Response(
csv,
mimetype="text/csv",
headers={"Content-disposition": f"attachment; filename={id}.csv"},
)
@self.flask_app.route("/api/v0/generate_plotly_figure", methods=["GET"])
@self.requires_auth
@self.requires_cache(["df", "question", "sql"])
def generate_plotly_figure(user: any, id: str, df, question, sql):
"""
Generate plotly figure
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
- name: chart_instructions
in: body
type: string
responses:
200:
schema:
type: object
properties:
type:
type: string
default: plotly_figure
id:
type: string
fig:
type: object
"""
chart_instructions = flask.request.args.get('chart_instructions')
try:
# If chart_instructions is not set then attempt to retrieve the code from the cache
if chart_instructions is None or len(chart_instructions) == 0:
code = self.cache.get(id=id, field="plotly_code")
else:
question = f"{question}. When generating the chart, use these special instructions: {chart_instructions}"
code = vn.generate_plotly_code(
question=question,
sql=sql,
df_metadata=f"Running df.dtypes gives:\n {df.dtypes}",
)
self.cache.set(id=id, field="plotly_code", value=code)
fig = vn.get_plotly_figure(plotly_code=code, df=df, dark_mode=False)
fig_json = fig.to_json()
self.cache.set(id=id, field="fig_json", value=fig_json)
return jsonify(
{
"type": "plotly_figure",
"id": id,
"fig": fig_json,
}
)
except Exception as e:
# Print the stack trace
import traceback
traceback.print_exc()
return jsonify({"type": "error", "error": str(e)})
@self.flask_app.route("/api/v0/get_training_data", methods=["GET"])
@self.requires_auth
def get_training_data(user: any):
"""
Get all training data
---
parameters:
- name: user
in: query
responses:
200:
schema:
type: object
properties:
type:
type: string
default: df
id:
type: string
default: training_data
df:
type: object
"""
df = vn.get_training_data()
if df is None or len(df) == 0:
return jsonify(
{
"type": "error",
"error": "No training data found. Please add some training data first.",
}
)
return jsonify(
{
"type": "df",
"id": "training_data",
"df": df.to_json(orient="records"),
}
)
@self.flask_app.route("/api/v0/remove_training_data", methods=["POST"])
@self.requires_auth
def remove_training_data(user: any):
"""
Remove training data
---
parameters:
- name: user
in: query
- name: id
in: body
type: string
required: true
responses:
200:
schema:
type: object
properties:
success:
type: boolean
"""
# Get id from the JSON body
id = flask.request.json.get("id")
if id is None:
return jsonify({"type": "error", "error": "No id provided"})
if vn.remove_training_data(id=id):
return jsonify({"success": True})
else:
return jsonify(
{"type": "error", "error": "Couldn't remove training data"}
)
@self.flask_app.route("/api/v0/train", methods=["POST"])
@self.requires_auth
def add_training_data(user: any):
"""
Add training data
---
parameters:
- name: user
in: query
- name: question
in: body
type: string
- name: sql
in: body
type: string
- name: ddl
in: body
type: string
- name: documentation
in: body
type: string
responses:
200:
schema:
type: object
properties:
id:
type: string
"""
question = flask.request.json.get("question")
sql = flask.request.json.get("sql")
ddl = flask.request.json.get("ddl")
documentation = flask.request.json.get("documentation")
try:
id = vn.train(
question=question, sql=sql, ddl=ddl, documentation=documentation
)
return jsonify({"id": id})
except Exception as e:
print("TRAINING ERROR", e)
return jsonify({"type": "error", "error": str(e)})
@self.flask_app.route("/api/v0/create_function", methods=["GET"])
@self.requires_auth
@self.requires_cache(["question", "sql"])
def create_function(user: any, id: str, question: str, sql: str):
"""
Create function
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: function_template
id:
type: string
function_template:
type: object
"""
plotly_code = self.cache.get(id=id, field="plotly_code")
if plotly_code is None:
plotly_code = ""
function_data = self.vn.create_function(question=question, sql=sql, plotly_code=plotly_code)
return jsonify(
{
"type": "function_template",
"id": id,
"function_template": function_data,
}
)
@self.flask_app.route("/api/v0/update_function", methods=["POST"])
@self.requires_auth
def update_function(user: any):
"""
Update function
---
parameters:
- name: user
in: query
- name: old_function_name
in: body
type: string
required: true
- name: updated_function
in: body
type: object
required: true
responses:
200:
schema:
type: object
properties:
success:
type: boolean
"""
old_function_name = flask.request.json.get("old_function_name")
updated_function = flask.request.json.get("updated_function")
print("old_function_name", old_function_name)
print("updated_function", updated_function)
updated = vn.update_function(old_function_name=old_function_name, updated_function=updated_function)
return jsonify({"success": updated})
@self.flask_app.route("/api/v0/delete_function", methods=["POST"])
@self.requires_auth
def delete_function(user: any):
"""
Delete function
---
parameters:
- name: user
in: query
- name: function_name
in: body
type: string
required: true
responses:
200:
schema:
type: object
properties:
success:
type: boolean
"""
function_name = flask.request.json.get("function_name")
return jsonify({"success": vn.delete_function(function_name=function_name)})
@self.flask_app.route("/api/v0/generate_followup_questions", methods=["GET"])
@self.requires_auth
@self.requires_cache(["df", "question", "sql"])
def generate_followup_questions(user: any, id: str, df, question, sql):
"""
Generate followup questions
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: question_list
questions:
type: array
items:
type: string
header:
type: string
"""
if self.allow_llm_to_see_data:
followup_questions = vn.generate_followup_questions(
question=question, sql=sql, df=df
)
if followup_questions is not None and len(followup_questions) > 5:
followup_questions = followup_questions[:5]
self.cache.set(id=id, field="followup_questions", value=followup_questions)
return jsonify(
{
"type": "question_list",
"id": id,
"questions": followup_questions,
"header": "Here are some potential followup questions:",
}
)
else:
self.cache.set(id=id, field="followup_questions", value=[])
return jsonify(
{
"type": "question_list",
"id": id,
"questions": [],
"header": "Followup Questions can be enabled if you set allow_llm_to_see_data=True",
}
)
@self.flask_app.route("/api/v0/generate_summary", methods=["GET"])
@self.requires_auth
@self.requires_cache(["df", "question"])
def generate_summary(user: any, id: str, df, question):
"""
Generate summary
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: text
id:
type: string
text:
type: string
"""
if self.allow_llm_to_see_data:
summary = vn.generate_summary(question=question, df=df)
self.cache.set(id=id, field="summary", value=summary)
return jsonify(
{
"type": "text",
"id": id,
"text": summary,
}
)
else:
return jsonify(
{
"type": "text",
"id": id,
"text": "Summarization can be enabled if you set allow_llm_to_see_data=True",
}
)
@self.flask_app.route("/api/v0/load_question", methods=["GET"])
@self.requires_auth
@self.requires_cache(
["question", "sql", "df"],
optional_fields=["summary", "fig_json"]
)
def load_question(user: any, id: str, question, sql, df, fig_json, summary):
"""
Load question
---
parameters:
- name: user
in: query
- name: id
in: query|body
type: string
required: true
responses:
200:
schema:
type: object
properties:
type:
type: string
default: question_cache
id:
type: string
question:
type: string
sql:
type: string
df:
type: object
fig:
type: object
summary:
type: string
"""
try:
return jsonify(
{
"type": "question_cache",
"id": id,
"question": question,
"sql": sql,
"df": df.head(10).to_json(orient="records", date_format="iso"),
"fig": fig_json,
"summary": summary,
}
)
except Exception as e:
return jsonify({"type": "error", "error": str(e)})
@self.flask_app.route("/api/v0/get_question_history", methods=["GET"])
@self.requires_auth
def get_question_history(user: any):
"""
Get question history
---
parameters:
- name: user
in: query
responses:
200:
schema:
type: object
properties:
type:
type: string
default: question_history
questions:
type: array
items:
type: string
"""
return jsonify(
{
"type": "question_history",
"questions": cache.get_all(field_list=["question"]),
}
)
@self.flask_app.route("/api/v0/", methods=["GET", "POST"])
def catch_all(catch_all):
return jsonify(
{"type": "error", "error": "The rest of the API is not ported yet."}
)
if self.debug:
@self.sock.route("/api/v0/log")
def sock_log(ws):
self.ws_clients.append(ws)
try:
while True:
message = ws.receive() # This example just reads and ignores to keep the socket open
finally:
self.ws_clients.remove(ws)
def run(self, *args, **kwargs):
"""
Run the Flask app.
Args:
*args: Arguments to pass to Flask's run method.
**kwargs: Keyword arguments to pass to Flask's run method.
Returns:
None
"""
if args or kwargs:
self.flask_app.run(*args, **kwargs)
else:
try:
from google.colab import output
output.serve_kernel_port_as_window(8084)
from google.colab.output import eval_js
print("Your app is running at:")
print(eval_js("google.colab.kernel.proxyPort(8084)"))
except:
print("Your app is running at:")
print("http://localhost:8084")
self.flask_app.run(host="0.0.0.0", port=8084, debug=self.debug, use_reloader=False)
class VannaFlaskApp(VannaFlaskAPI):
def __init__(
self,
vn: VannaBase,
cache: Cache = MemoryCache(),
auth: AuthInterface = NoAuth(),
debug=True,
allow_llm_to_see_data=False,
logo="https://img.vanna.ai/vanna-flask.svg",
title="Welcome to Vanna.AI",
subtitle="Your AI-powered copilot for SQL queries.",
show_training_data=True,
suggested_questions=True,
sql=True,
table=True,
csv_download=True,
chart=True,
redraw_chart=True,
auto_fix_sql=True,
ask_results_correct=True,
followup_questions=True,
summarization=True,
function_generation=True,
index_html_path=None,
assets_folder=None,
):
"""
Expose a Flask app that can be used to interact with a Vanna instance.
Args:
vn: The Vanna instance to interact with.
cache: The cache to use. Defaults to MemoryCache, which uses an in-memory cache. You can also pass in a custom cache that implements the Cache interface.
auth: The authentication method to use. Defaults to NoAuth, which doesn't require authentication. You can also pass in a custom authentication method that implements the AuthInterface interface.
debug: Show the debug console. Defaults to True.
allow_llm_to_see_data: Whether to allow the LLM to see data. Defaults to False.
logo: The logo to display in the UI. Defaults to the Vanna logo.
title: The title to display in the UI. Defaults to "Welcome to Vanna.AI".
subtitle: The subtitle to display in the UI. Defaults to "Your AI-powered copilot for SQL queries.".
show_training_data: Whether to show the training data in the UI. Defaults to True.
suggested_questions: Whether to show suggested questions in the UI. Defaults to True.
sql: Whether to show the SQL input in the UI. Defaults to True.
table: Whether to show the table output in the UI. Defaults to True.
csv_download: Whether to allow downloading the table output as a CSV file. Defaults to True.
chart: Whether to show the chart output in the UI. Defaults to True.
redraw_chart: Whether to allow redrawing the chart. Defaults to True.
auto_fix_sql: Whether to allow auto-fixing SQL errors. Defaults to True.
ask_results_correct: Whether to ask the user if the results are correct. Defaults to True.
followup_questions: Whether to show followup questions. Defaults to True.
summarization: Whether to show summarization. Defaults to True.
index_html_path: Path to the index.html. Defaults to None, which will use the default index.html
assets_folder: The location where you'd like to serve the static assets from. Defaults to None, which will use hardcoded Python variables.
Returns:
None
"""
super().__init__(vn, cache, auth, debug, allow_llm_to_see_data, chart)
self.config["logo"] = logo
self.config["title"] = title
self.config["subtitle"] = subtitle
self.config["show_training_data"] = show_training_data
self.config["suggested_questions"] = suggested_questions
self.config["sql"] = sql
self.config["table"] = table
self.config["csv_download"] = csv_download
self.config["chart"] = chart
self.config["redraw_chart"] = redraw_chart
self.config["auto_fix_sql"] = auto_fix_sql
self.config["ask_results_correct"] = ask_results_correct
self.config["followup_questions"] = followup_questions
self.config["summarization"] = summarization
self.config["function_generation"] = function_generation and hasattr(vn, "get_function")
self.config["version"] = importlib.metadata.version('vanna')
self.index_html_path = index_html_path
self.assets_folder = assets_folder
@self.flask_app.route("/auth/login", methods=["POST"])
def login():
return self.auth.login_handler(flask.request)
@self.flask_app.route("/auth/callback", methods=["GET"])
def callback():
return self.auth.callback_handler(flask.request)
@self.flask_app.route("/auth/logout", methods=["GET"])
def logout():
return self.auth.logout_handler(flask.request)
@self.flask_app.route("/assets/")
def proxy_assets(filename):
if self.assets_folder:
return send_from_directory(self.assets_folder, filename)
if ".css" in filename:
return Response(css_content, mimetype="text/css")
if ".js" in filename:
return Response(js_content, mimetype="text/javascript")
# Return 404
return "File not found", 404
# Proxy the /vanna.svg file to the remote server
@self.flask_app.route("/vanna.svg")
def proxy_vanna_svg():
remote_url = "https://vanna.ai/img/vanna.svg"
response = requests.get(remote_url, stream=True)
# Check if the request to the remote URL was successful
if response.status_code == 200:
excluded_headers = [
"content-encoding",
"content-length",
"transfer-encoding",
"connection",
]
headers = [
(name, value)
for (name, value) in response.raw.headers.items()
if name.lower() not in excluded_headers
]
return Response(response.content, response.status_code, headers)
else:
return "Error fetching file from remote server", response.status_code
@self.flask_app.route("/", defaults={"path": ""})
@self.flask_app.route("/")
def hello(path: str):
if self.index_html_path:
directory = os.path.dirname(self.index_html_path)
filename = os.path.basename(self.index_html_path)
return send_from_directory(directory=directory, path=filename)
return html_content
```
The content has been capped at 50000 tokens, and files over NaN bytes have been omitted. The user could consider applying other filters to refine the result. The better and more specific the context, the better the LLM can follow instructions. If the context seems verbose, the user can refine the filter using uithub. Thank you for using https://uithub.com - Perfect LLM context for any GitHub repo.